- Published on
gzip 압축 방식 정리
- Authors

- Name
- 이건창
Introduction
- 개요
- gizp 방식이 뭘까?
- 궁금증
- 궁금증 1 : gzip 압축 레벨을 결정할 수 있는데 어디에서 결정하고 있는걸까?
- 궁금증 2 : CRC32 체크섬 데이터는 어디에 저장되는걸까?
- 궁금증 3 : 왜 gzip 일까?
개요
로그 파일 10MB 파일을 gzip 압축하면 용량이 250KB 까지 감소했다. 어떻게 압축 효과가 좋은지 확인하기 위해서 정리했다.
gizp 방식이 뭘까?
gizp 은 LZ77 알고리즘과 Huffman 코딩으로 문자열을 압축한다.
- LZ77 알고리즘 : 슬라이딩 윈도우를 사용해 문자열을 압축한다.
- Huffman 코딩 : 문자열을 압축하는 방식으로 가장 빈번한 문자열을 가장 짧은 비트로 표현한다.
추가적인 특징은 CRC32 체크섬을 사용해 데이터 무결성을 검증한다.
궁금증
- 궁금증 1 : gzip 압축 레벨을 결정할 수 있는데 어디에서 결정하고 있는걸까?
- 궁금증 2 : CRC32 체크섬 데이터는 어디에 저장되는걸까?
- 궁금증 3 : 왜 gzip 일까?
궁금증 1 : gzip 압축 레벨을 결정할 수 있는데 어디에서 결정하고 있는걸까?
gzip 압축 레벨은 0 ~ 9 까지 설정할 수 있고 높을 수록 압축률이 높고 낮을 수록 속도가 빠르다. GZIPOutputStream 은 6으로 설정되고 압축 레벨 변경할 수 없다.
new Deflater(Deflater.DEFAULT_COMPRESSION, true) 형태로 주입되며 -1 값이다.
public GZIPOutputStream(OutputStream out, int size, boolean syncFlush)
throws IOException
{
super(out, out != null ? new Deflater(Deflater.DEFAULT_COMPRESSION, true) : null,
size, syncFlush);
usesDefaultDeflater = true;
writeHeader();
crc.reset();
}
궁금증 2 : CRC32 체크섬 데이터는 어디에 저장되는걸까?
파일 마지막 부분에서 진행된다. 8 바이트로 구성된 TRAILER_SIZE 가 있다. TRAILER에는 압축되기 전 데이터의 CRC32 체크섬과 압축되기 전 크기가 저장된다. Integer 유형이라 4바이트씩 할당된다.
private void writeTrailer(byte[] buf, int offset) throws IOException {
writeInt((int)crc.getValue(), buf, offset); // CRC-32 of uncompr. data
writeInt(def.getTotalIn(), buf, offset + 4); // Number of uncompr. bytes
}
또잉 작성할 때 순서를 변경해서 저장하고 있는데, 리틀엔디안 방식을 차용하고 있었다. 왜인지 모르겠다.
/*
* Writes integer in Intel byte order to a byte array, starting at a
* given offset.
* */
private void writeInt(int i, byte[] buf, int offset) throws IOException {
writeShort(i & 0xffff, buf, offset);
writeShort((i >> 16) & 0xffff, buf, offset + 2);
}
/*
* Writes short integer in Intel byte order to a byte array, starting
* at a given offset
* */
private void writeShort(int s, byte[] buf, int offset) throws IOException {
buf[offset] = (byte)(s & 0xff);
buf[offset + 1] = (byte)((s >> 8) & 0xff);
}
The
bytesitem of theCONSTANT_Integer_infostructure represents the value of theintconstant. The bytes of the value are stored in big-endian (high byte first) order.
4.4.4. The CONSTANT_Integer_info and CONSTANT_Float_info Structures에서는 Integer 바이트 배열은 빅엔디언으로 저장된다고 했는데 왜 리틀 앤디언을 사용하고 있을까?
Gzip RFC 문서 스펙에서 최하위 비트가 낮은 위치 주소에 저장한다고 한다.
Within a computer, a number may occupy multiple bytes. All multi-byte numbers in the format described here are stored with the least-significant byte first (at the lower memory address). For example, the decimal number 520 is stored as:
설명하자면 520 을 2진수로 표현하면 1000001000이다. 메모리에 순차 저장하면 다음처럼 저장된다.
1 0
+--------+--------+
|00000010|00001000|
+--------+--------+
^ ^
| |
| + 2 ^ 3
+ 2 ^ 9
비트는 자신 값이 변경되면 왼쪽 값을 변경한다. 그래서 왼쪽 값을 상위 비트라고 표현합니다. 그럼 최상위 비트는 7이고 최하위 비트는 0이다.
+--------+
|76543210|
+--------+
그러나 Gzip 은 최하위 비트 먼저 저장한다. 즉, 순서가 변경된다.
0 1
+--------+--------+
|00001000|00000010|
+--------+--------+
^ ^
| |
| + 2 ^ 9
+ 2 ^ 3
자바 코드 동작 방식은 다음과 같다.

궁금증 3 : 왜 gzip 일까?
해당 자료에서 압축이 가장 빠른 방법이라고 한다. 그런데 추출은 차이가 없어 보인다. 비교대상은 ZIP, GZIP, BZIP2 이다.
압축 성능 측면에서 비교 자료다.
BZIP2 > GZIP >= ZIP

속도 측면에서 비교 자료다.
GZIP >= ZIP > BZIP2
| 파일 크기 대비 추출 시간 비교 | 파일 크기 대비 압축 시간 비교 |
|---|---|
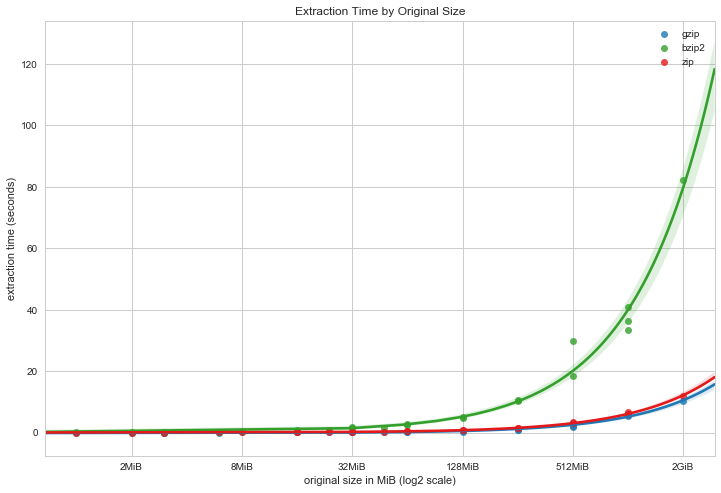 | 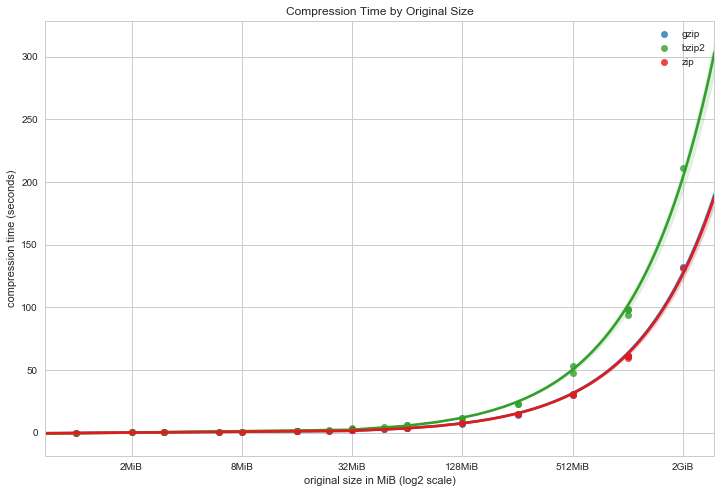 |
WIKI에서 ZIP과 GZIP 비교점은 ZIP 중 DEFLATE 알고리즘을 사용하면 GZIP과 동일하다. 그래서 ZIP과 GZIP은 유사한 성능을 보여주는 모습을 볼 수 있다.