- Published on
상상까지 더 한 알림 시스템 개선기
- Authors

- Name
- 이건창
서론
주제 이유
- 대량건 발송하기 위해 알림시 스템 개선 작업 필요하다.
- 단계적 성장을 모두 경험하기 어려우니
요구 처리량과 관계 없이 고민할 수 있을만큼 설계해보기 위해서 주제를 선정했다.
준비하게 된 계기
이 문서는 사용자가 1명일 때와 1억명일 때의 시스템 구조 차이를 살펴보고, 알림 기능의 성능 개선 과제를 수행하면서 얻은 경험과 통찰을 공유하는 것을 목표한다. 구 처리량에 관계없이 시스템 개선을 위한 다양한 접근 방식을 고민해보고, 이를 통해 더 나은 성능을 달성할 수 있는 방법을 모색해본다.

목표
- 필요에 따라 쉽게 확장 가능하도록 구성한다.
- 학습 목적이기 때문에 곧바로 큐 시스템을 채택하지 않았다.
본론
1. 알림 특징을 이용한 상태 변화 디자인
목표
- 프로젝트를 설계하면 객체가 생성되고 소멸되는 동적인 모든 상황들을 정적인 코드로 담아야 한다. 그렇기에 시간에 흐름에 따라 유연하게 변경이 가능하면서 동시에 모든 상황들을 대비할 수 있도록 견고하게 설계해야 한다.
알림 발송 기능은 다음과 같은 특징을 가진다.
- 알림은 한 명의 사용자에게 메시지를 전달한다.
- 알림은 하나의 메시지로 단체 발송이 가능하다.
- 알림은 상태에 따라 관리하는 방법이 다르다.
- 알림 정보는 변하지 않는다.
우린 추상화에 대해서 공부했다. 추상화를 통해 공통 요소를 줄이고 상태로 구분해 클래스 간 관계를 명확하게 정의할 수 있다.
추상화는 대상의 구체적인 형상이 아닌 점, 선, 면, 색 등 순수한 조형 요소로 표현한 미술의 한 가지 흐름이다. 자바에서 추상화는 공통된 특징을 묶고 공통되지 않은 특징을 분리해 반복되는 코드를 줄이고 객체 간 차이를 명확하게 가져간다.
알림은 상태만 변화하고 내부 정보는 변하지 않는 점을 고려한다면 다음처럼 객체 구성이 가능하다.

객체지향은 객체 간 행동을 중심으로 생각하며 협력관계를 구축해 해당 역할에 들어가는 개체들의 자율성을 보장하게 된다. 덕분에 쉽게 교쳬 가능하다는 장점이 있다. 객체 지향에서는 행동도 객체가 될 수 있다.
행동이 객체로 표현된 클래스는 다음과 같다.
- StandbyNotification
- SendNotification
- CompleteNotification
- FailNotification
- FailbackNotification
행동의 결과물로 나오는 상태는 다음과 같다.
- RequestNotification
- PendingNotification
- SendingNotification
- CompletedNotification
- FailedNotification

- 참고하면 좋을 자료 : https://youtu.be/poPZvLi0O08?si=H1so9gPpggnElA1f
- 참고하면 좋을 자료 : https://m.yes24.com/Goods/Detail/18249021
알림 상태로 객체를 구분짓고 동적으로 변화하는 상태를 관리하기 위해 행동을 객체로 표현해 객체 간 협력 관계를 구축했다. 협력 관계가 서비스가 되면서 객체 간 협력보단 절차적인 실행 흐름이 된게 아닐까하는 아쉬움도 있었다.
아쉬움을 뒤로한 체 본격적으로 시스템 구성에 들어가보겠다.
2. 단일 서버로 구현
단일 서버부터 출발해본다. 사용자가 적다면 가장 단순한 구현이 좋아보였고 실행에 옮겼다. 알림 발송 건수가 적은 경우 설계는 다음과 같다.

연결된 모든 클라이언트는 알림 발송이 완료될 때까지 대기하게 된다. 알림 발송이 늦어진다면 다음과 같은 이슈가 발생한다.
- 대기 시간이 길어질 수록
read timeout,connection timeout으로 인한 요청 실패에 노출될 가능성이 높아진다. - 알림 발송 기능 장애가 클라이언트 측으로 전파된다.
- 클라이언트는 응답을 받기 위해 스레드를 대기(
TIMED_WAITING) 상태로 유지하기 때문에 리소스 낭비가 존재한다.
알림 발송 결과로 인해 클라이언트의 요청이 실패할 수 있는 상황이다.

알림 발송 기능으로 인한 장애 전파와 리소스 낭비를 줄이기 위해 클라이언트의 요청과 알림 발송 기능을 분리해봤다.
3. 장애 전파 문제 해결 : 비동기로 사용자 요청과 알림 발송 요청 동작 분리
사용자 요청과 알림 전송을 비동기로 처리해 알림 전송에 따라 응답 시간이 의존되는 현상 해결한다. 비동기로 처리하면 다음과 같이 동작한다.

비동기 방식으로 간단하게 스케줄러를 이용했다. 스케줄링 특성에 맞게 어떠 방식을 사용할지 결정하면 된다.

- cron
- 특정 시간에 실행
- fixedDelay
- 작업 사이 간격을 두고 실행
이 때 알림 발송 요청 받으면 200 OK를 반환하게 된다. 즉, 알림 발송 요청은 무조건 전송되어야 한다는 뜻이다. 이런 경우 알림 발송 요청 행동의 부산물인 PendingNotification, CompletedNotification, FailedNotification 상태를 영속화한다면 사용자 요청을 보장할 수 있다.

행동의 결과인 상태를 영속화하지 않는다면 서버는 상태를 가지고 있기 때문에 서버가 재시작되거나 종료되면 사용자 요청을 유실하게 된다. 데이터베이스 등과 같은 스토리지 시스템을 사용한다면 서버는 상태를 가지지 않게 되어 확장 또한 쉽다.
작은 그림으로 살펴보자. 우린 의도한대로 알림 발송 요청과 사용자 요청을 분리해 처리할 수 있게 되었다. 그러나 한 건 처리할 때마다 5초 걸리는 건 사실이다.

사용자 요청은 영속화되어 관리되고 알림 발송 요청은 비동기로 처리되어 사용자 요청에 영향을 주지 않는다. 우리가 원하는대로 알림 발송으로 인해 사용자 요청이 유실될 가능성을 줄였지만 작업자의 전송량에 따라 알림 발송 처리량이 결정된다.
알림 발송 응답을 대기하지 않고 지속적으로 요청한다면 처리량을 높일 수 있지 않을까?
4. 처리량 문제 해결 : 비동기로 요청 기다리지 않고 대량 발송하기
알림 발송 요청을 대기하지 않고 새롭게 스레드를 생성해 알림 발송 요청한다면 처리량을 높일 수 있다.

해당 방식은 @Async 애너테이션으로 해결했다.

@Async 애너테이션을 이용할 때 작업자를 정의할 수 있는데 얼만큼 어떻게 처리할지 결정하는 요소로 매우 중요하다.

ThreadPool 작업자 설정은 다음으로 결정된다.
- corePoolSize
- 작업을 처리하는 작업자들 크기
- maxPoolSize
- 작업을 처리하는 작업자들의 한계치
- queueCapacity
- 처리할 작업이 대기 가능한 허용량
동작은 딱 4 가지만 기억하면 된다.
- corePoolSize 만큼 작업이 진행중이지 않다면 작업 진행
- corePoolSize 만큼 작업이 진행중이면 queueCapacity 만큼 적재
- queueCapacity 에 가득찼다면 corePoolSize가 넘더라도 실행
- queueCapacity 에 가득찼다면 corePoolSize가 넘었는데 maxPoolSize 만큼 찼다면 해당 작업은 거절
corePoolSize가 넘었는데 maxPoolSize 만큼 차서 거절되면 다음 정책으로 처리한다.
- AbortPolicy
- TaskRejectedException 예외 발생! (기본값)
- CallerRunsPolicy
- 실행중인 메서드에서 호출된 스레드가 직접 실행
- DiscardPolicy
- 무시
종료와 관련된 옵션 정의도 필요하다.
- waitForTasksToCompleteOnShutdown
- 작업 모두 실행될 때까지 종료 대기 여부
- awaitTerminationSeconds
- 작업이 전부 실행됨을 확인하고 대기하는 시간
기본적으로 작업이 종료될 때까지 대기하지 않는다. awaitTerminationSeconds 변수를 이용해 일정 시간동안 스프링 컨테이너가 내려가지 않게 한다.
이렇게 까지 설정한다면 작업자는 스레드를 생성해 요청하도록 위임한다. 이 때, 요청을 보낼따마다 스레드를 생성한다면 리소스 낭비가 발생한다. 이 문제를 해결하기 위해 WebClient를 사용해보자.

5. 리소스 낭비 문제 해결 : WebClient로 사용자 요청 처리하기
WebClient를 이용한다면 요청마다 스레드를 생성하지 않고 요청을 처리할 수 있다. WebClient 내부에서 스레드 풀을 이용해 요청을 보내고 응답 신호가 오면 응답을 받아 전달하게 된다.

WebClient는 요청을 보낼따마다 스레드를 생성한다면 리소스 낭비를 극복할 수 있도록 도와준다.
이 떄 Http Interface Client를 이용한다면 RestTemplate, RestClient -> WebClient 교체가 정말 간단하다.
AS-IS

TO-BE

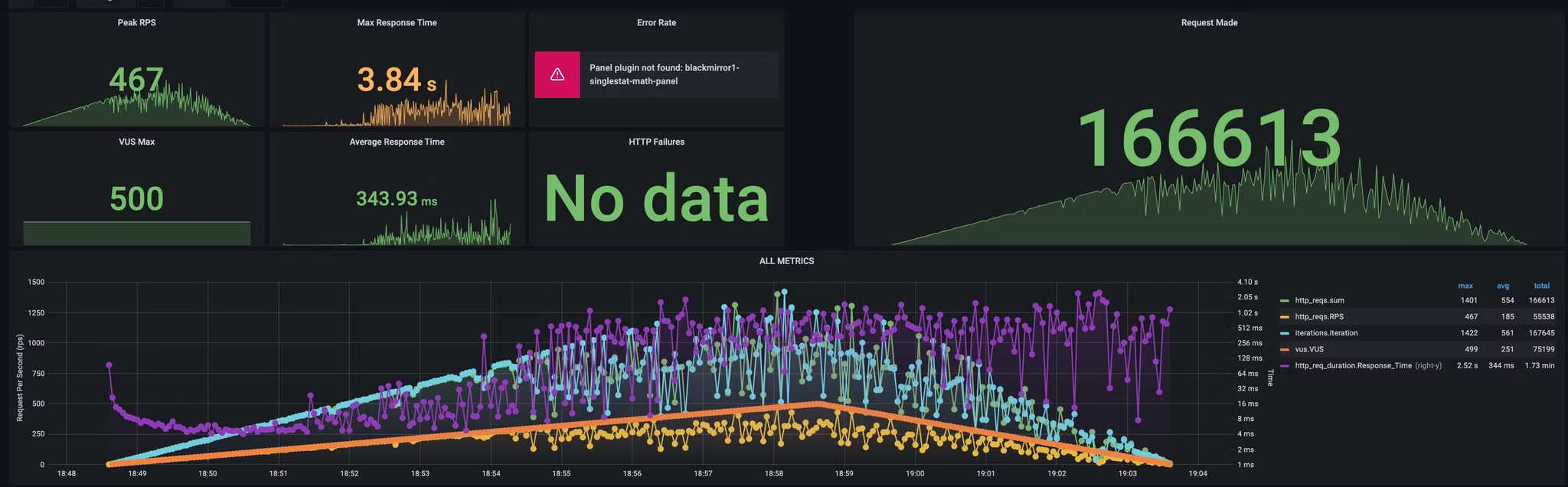
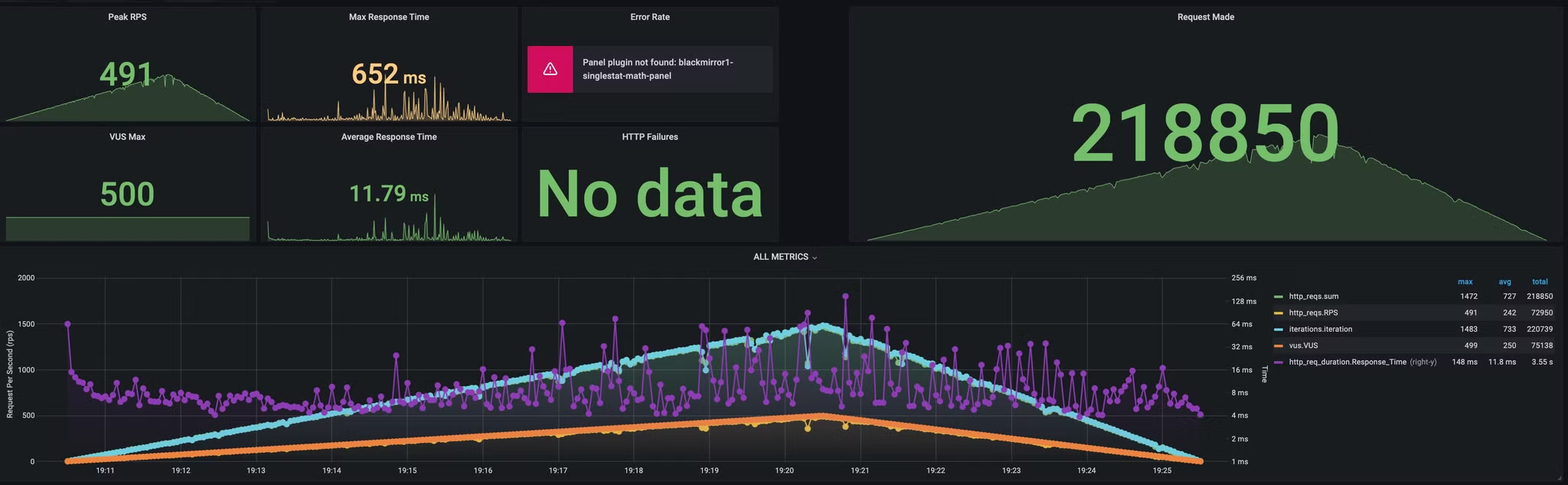
restclient 와 webclient 사용한 경우 비교해봤다.
- 최대 VUser 500 램프 업
스레드 상태부터 확인하면 restclient는 요청 보내기 전에 대기하는 스레드가 13k 나 대기한다. 반면 webclient는 대기하는 요청 수가 2 정도다.
| restclient | webclient |
|---|---|
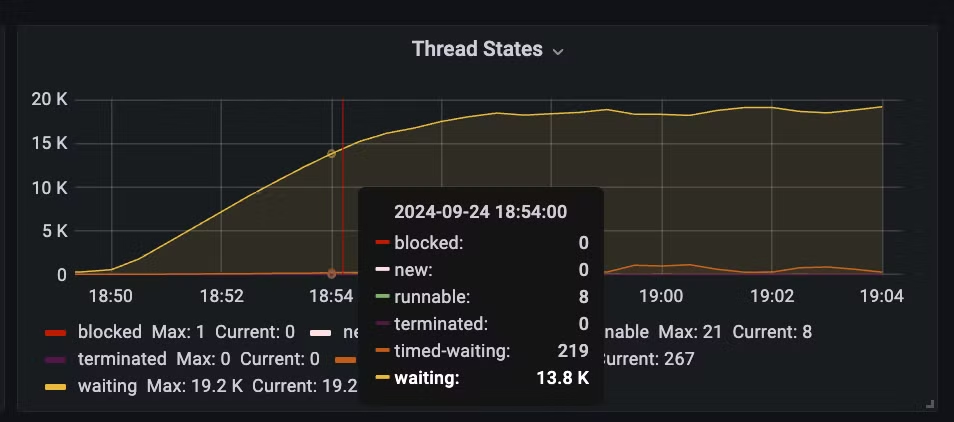 | 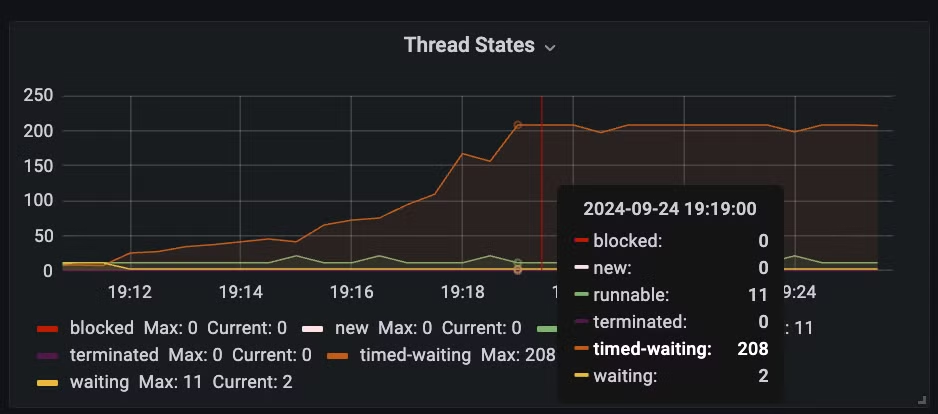 |
- waiting thread : pool 고갈로 대기하는 스레드 수
- timed-waiting : 통신 후 응답을 대기하는 스레드 수
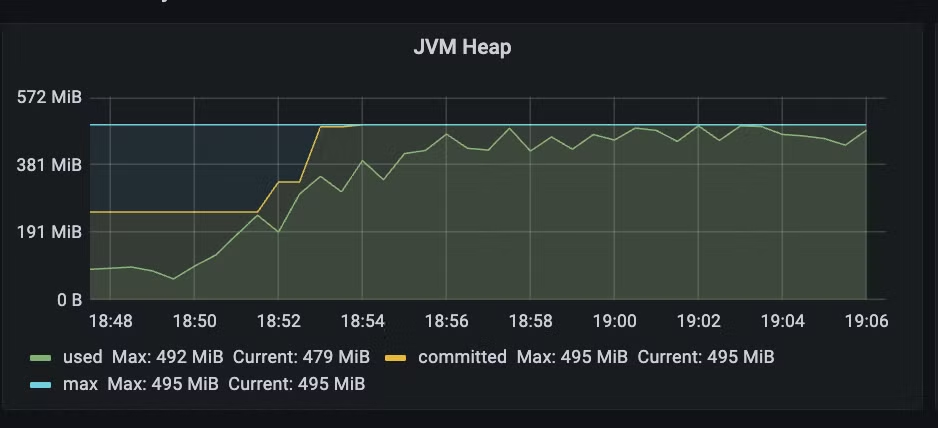
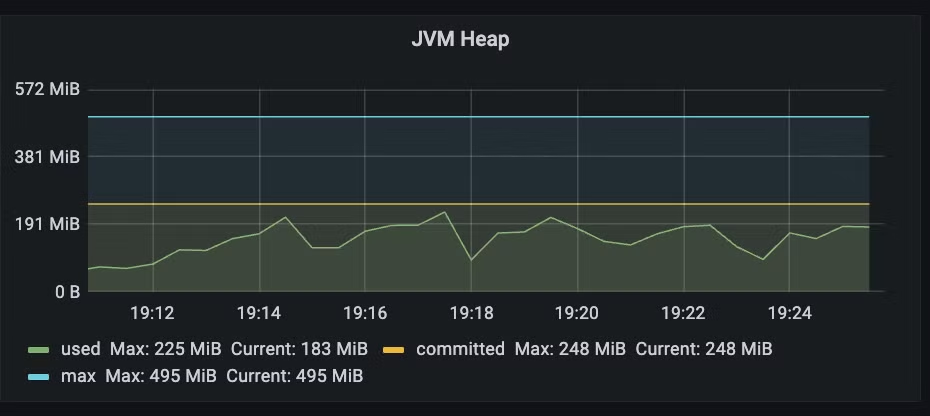
restclient를 사용하면서 요청 당 스레드를 하나씩 생성하기 때문에 메모리 소모도 극심하다. 반면 webclient는 스레드 풀을 이용해 요청을 보내기 때문에 메모리 소모가 적다.
| restclient | webclient |
|---|---|
 |  |
restclient는 요청 대기 덕분에 응답 시간이 길어진다. 반면 webclient는 스레드 풀을 이용해 요청을 보내기 때문에 응답 시간이 짧다.
| restclient | webclient |
|---|---|
 |  |
물론 저렇게 변경한다고 이전처럼 동작하지 않는다. 슬프게도 우린 Reactive하게 코드를 작성해야 한다.

WebClient 단점은 Webflux와 같은 Reactive 라이브러리가 의존성에 추가되어야 한다는 점이다. WebClient를 사용하기 위해 Webflux 의존성 추가는 러닝커브를 늘리는 일이니 조심스럽다.
한 대의 서버로 리소스를 효율적이게 처리하는 과정은 모두 준비됐다. 그러나 한 대의 서버로는 처리량 한계가 존재할 수 있다. 읽는 속도는 빠르지만 처리 속도는 현저히 느리기 때문이다.

개선한 상황에서도 time-waiting 스레드가 증가하게 되어 서비스 장애로 이어질 수 있다.

우리는 이런 상황을 타개해야 한다.

이를 해결하기 위해 멀티 인스턴스로 구성해보자.
6. 처리량 한계 문제 해결 : 멀티 인스턴스 구성
공유 데이터를 외부에서 관리한다면 다음처럼 멀티 인스턴스로 구성할 수 있다.

많아진 알림 발송 전송을 처리하기 위해서는 작업자를 늘릴 수 있어야 한다. 기존에는 스토리지에서 보낼 데이터를 청크 단위로 꺼내 전송했다.

병렬처리 수행하기 위해 어떤 위치부터 수행할지 파악할 수 있는 카운팅 공유 데이터를 만들었다. 특정 작업자가 대기상태알림을 조회하면 카운팅을 읽으만큼 증가시키면 다음 작업자는 다음 칸 대기상태알림을 조회한다. 특정 작업자가 알림을 전송하면 기존 데이터를 지우고 지운 만큼 카운팅을 감소시킨다.

이렇게 공유 데이터로 읽어야 할 위치를 서로 공유한다면 문제 없이 병렬처리가 가능하다.
병렬 처리 이점은 멀티 인스턴스로 쉽게 확장 가능하다는 점이다. 확장이 가능하다면 단일 서버 형태만 가지는 리소스 낭비를 줄일 수 있다.
파편화로 예시를 듣나면 파편화 크기가 적을 수록 리소스 오남용이 적어진다. 서버 리소스를 줄요 멀티 인스턴스로 관리한다면 트래픽에 맞게 리소스 활용이 가능하다.
병렬 처리 덕분에 다음과 같은 장점을 가질 수 있었다.
- 처리율을 원하는 만큼 높일 수 있다.
- 멀티 인스턴스로 쉽게 변경 가능하다.
예시로는 간단하게 애플리케이션 내부에서 락을 이용해 동시성을 제어했지만 멀티 인스턴스에서는 분산락을 적용하면 된다.

이건 주변에 자료가 많으니 패스하겠다.
반면 작업자가 많아지면서 스토리지 부하가 많아질테다. 스토리지 부하 분산을 위해 저장소 스케일링 진행이 필요하다. 알림 발송 서버가 멀티 인스턴스로 구축되면서 저장소에 접근하는 빈도가 많아지게 된다.

스토리지 부하 이슈에 대한 대응이 필요하다.
7. 스토리지 부하 문제 해결 : 스토리지 스케일링 진행
스토리지를 스케일링 한다면 알림 서버가 증설되는 상황에 쉽게 대응 할 수 있다. 필자는 간단하게 모듈러 연산으로 샤딩을 수행했다.

이 때 shardingsphere 라이브러리를 이용했는데 코드 수정 없이 쉽게 샤딩 할 수 있었다. orm도 함께 사용가능하니 도입해보자.
spring:
application:
name: forwarder1
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
url: jdbc:shardingsphere:classpath:sharding.yml
jpa:
hibernate:
ddl-auto: create-drop
properties:
hibernate:
dialect: org.hibernate.dialect.MySQLDialect
classpath에 sharding.yml 파일을 추가하면 된다.
dataSources:
ds0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
# https://deeplify.dev/database/troubleshoot/public-key-retrieval-is-not-allowed 이슈 발생했었음.
jdbcUrl: jdbc:mysql://localhost:3306/forwarder0?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: test
ds1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
# https://deeplify.dev/database/troubleshoot/public-key-retrieval-is-not-allowed 이슈 발생했었음.
jdbcUrl: jdbc:mysql://localhost:3306/forwarder1?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: test
rules:
- !SHARDING
tables:
pending_notification:
actualDataNodes: ds${0..1}.pending_notification
failed_notification:
actualDataNodes: ds${0..1}.failed_notification
completed_notification:
actualDataNodes: ds${0..1}.completed_notification
defaultDatabaseStrategy:
standard:
shardingColumn: channel_key
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
# https://shardingsphere.apache.org/document/5.5.0/en/dev-manual/sharding/
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds${channel_key.hashCode() % 2}
props:
sql-show: false
동작에 의문이 들 수 있는데, shardingsphere는 spring boot 덕분에 auto config된 datasource 정보를 본인이 가진 정보로 라우팅하는 역할을 한다고 이해하면 좋다.

순서를 보장하고 싶다면 도메인을 고민해볼 필요가있다. 순서면 사용자가 알림을 받는 순서를 말하는걸까? 그럼 한 사용자에게만 순서를 보장하면 되겠네? 라는 생각하면 모듈러 연산을 진행할 키워드가 선정된다.

이 때 모듈러 연산에 사용할 키워드 선정이 매우 중요하다. 만약 사용자 식별자로 모듈러 연산을 진행한다면 다음과 같은 이점과 단점이 있다.
- 이점
- 동일한 사용자는 동일한 스토리지에 저장되므로 알림 발송 요청 순서에 맞게 전송할 수 있다.
- 단점
- 동일한 사용자는 동일한 스토리지에 저장되므로 특정 데이터베이스에만 저장과 조회가 집중되는 핫키 현상이 발생한다.
모듈러 연산으로 저장할 때 특정 키워드로 동일한 스토리지를 유지해야 하는 경우에는 해당 키워를 활용하는게 좋지만 한 사용자에게 과도한 알림이 전송된다면 부하 분산한 의미가 없어진다.

핫 키 문제는 해결해야 할 과제다.
8. 핫키 문제 해결 : 중복도 낮추기
핫키를 해결하기 위해서 키워드를 고르게 분산해야 한다. 즉, 특정 키워드를 모듈러 연산한 결과 값의 중복된 수치가 적을수록 핫키 문제를 줄일 수 있다.
- 특정 키워드의 중복도를 낮춘다.
- 만약 한 사용자에 대한 순차적인 처리를 보장하고 싶었다면 분 단위 전송 시간과 사용자 식별자를 조합해 모듈러 연산을 진행하면서 중복된 수치를 줄일 수 있다.
- 가상 노드를 활용한 해시링을 사용한다.
- 해시링은 스토리지 스케일링에 대응하기 쉽게 나온 개념이다. 해시링의 단점은 데이터가 균등하게 분포하지 못한다는 점인데, 가상 노드를 활용한다면 균등하게 분포할 수 있다.
상황에 맞게 둘 중 하나를 사용한다면 핫키 문제를 해결할 수 있다. 스토리지 스케일링이 빈번하다면 해시링을 활용하는게 좋겠지만 그렇지 않다면 단순하게 특정 키워드에 대한 중복도를 낮춘는게 좋은 솔루션으로 보인다.
필자는 분 단위로 사용자의 알림 순서를 보장 할 수 있도록 모듈러 연산을 수행했다. 핫 키 이슈가 어느정도 해결되리라 예상된다.

알림 특성상 특정 시간대에 요청이 몰리기 때문에 급증하는 트래픽에서 분 단위로 분할 하는 방법은 좋은 해결책이 아니라고 생각한다. 분 단위 분할에 의존적이지 않은 가상 노드를 이용한 해시링을 사용하면 급증하는 트래픽에 대응할 수 있지 않을까.
9. 결론
- 시스템 추가는 쉽지만 수정은 어렵다. 시스템 추가에 신중한 편이라 기존 시스템으로 해결 가능하다면 해결하는 편이다.
- 객체지향은 객체 간 행동을 중심으로 생각하며 협력관계를 구축해 해당 역할에 들어가는 객체들의 자율성을 보장하게 된다. 행동을 중심으로 상태 변화를 캐치해 객체들의 자율성을 보장하는 환경을 경험할 수 있었다.
- 구현하면서 느낀점은 대기 상태 알림을 전송하는 과정에서 push, pull 동작을 수행하는 스토리지를 사용하면 쉽게 구현할 수 있어보였다. 괜찮다면 RabbitMQ와 같은 큐 시스템을 사용해 개선하면 좋아보인다.