- Published on
6. 광고 클릭 이벤트 집계
- Authors

- Name
- 이건창
1 단계 : 문제 이해 및 설계 범위 확장
설계 범위 좁히기
- 서비스 기준
- 입력 데이터 형태
- 데이터 양
- 필요한 쿼리
- 엣지 케이스
- 지연 시간 요건
요구사항 정제
- 기능 요구사항 정제
- 일정 시간 동안 클릭수 집계
- 일정 시간 동안 많이 클릭된 상위 100개 광고 아이디 반환
- 데이터 양은 페이스북이나 구글 규모
- 비기능 요구사항 정제
- 집계 결과 정확성은 정산에 필요하므로 중요
- 지연된거나 중복된 이벤트를 적절히 처리해야 함
- 부분적인 장애를 견딜 견고성 필요함
- 전체 처리 시간은 일정 시간 단위를 넘지 않아야 함
일반적으로 요구되는 기능
- 짧은 지연 시간
- 갱신 지연 시간을 의도에 맞춰 쉽게 줄일 수 있는 환경이 만들어져야 한다.
- 확장성
- 자원을 투자 비례해 성능 향상이 쉽게 되어야 한다.
- 유연성
- 최소한 유지 보수 비용으로 기능 추가나 수정이 가능해야 한다.
2 단계 : 개략적 설계안 제시 및 동의 구하기
데이터 모델
데이터 모델을 살펴보면 원시 데이터를 받게 되면 집계 결과를 계산한다. 사용자는 집계 결과만 확인하기 때문에 집계 결과만 저장하게 된다면 다음과 같은 문제가 발생한다.
- 원시 데이터가 존재하지 않으면 디버깅이 어렵다.
- 원시 데이터는 백업 데이터로 활용한다.
- 대용량 데이터 집합은 예상 밖 인사이트를 가지고 있는데 원시 데이터 활용도가 높다.
비동기 처리
생산자와 소비자 용량이 항상 같을 수 없다. 유동적인 트래픽에 대비하기 위해서는 생산자와 소비자 연결을 끊는게 좋다. 책에서는 카프카를 추천한다.
집계 서비스
맵리듀스 프레임워크를 사용한다. 맵리듀스에 좋은 모델은 유향 비순환 그래프(DAG)이다. 맵리듀스의 동작은 단순하다. 시스템을 노드 단위로 나누고 맵, 집계, 리듀스 작업으로 세분화한다.
- 맵 노드 : 데이터 필터링과 변환 역할을 담당한다.
- 집계 노드 : 메모리에서 데이터 집계를 담당한다.
- 리듀스 노드 : 산출 결과를 집계해 최종 결과로 축약한다.
유향 비순환 그래프 특징을 이용해 리듀스 결과를 계속 축약하다보면 원하는 결과가 나오게 된다.
유향 비순환 그래프(DAG)는 방향 순환이 없는 무한 유향 그래프이다. 즉, 위상정렬이 있는 유향 그래프라고 보면 된다. 현실에서 사용 예는 스프레드 시트가 있다. 스프레드 시트는 각 셀을 참조하게 되며 최상위 셀 값을 수정하면 하위 셀 값들도 변경된다.
3 단계 : 상세 설계
집계 방법
집계 방법에는 스트리밍 방식과 일괄 처리 방식이 있다. 데이터 제공 시점을 파악해 어떤 방식을 선택할지 고려한다.
| 일괄 처리 | 스트리밍 처리 | |
|---|---|---|
| 성능 측정 기준 | 처리량 | 처리량, 지연시간 |
| 사례 | 맵리듀스 | 플링크 |
광고 클릭 이벤트 집계 핵심 아이디어는 단일 스트림 처리 엔진을 사용해 실시간 데이터 처리 및 데이터 재처리 문제를 해결하는 일이다. 아키텍처는 카파를 따른다.
데이터 재계산
집계 데이터를 재계산 하는 경우를 대비해 실시간 데이터 처리 과정에 간섭하지 않고 재처리하는 프로세스를 구성해야 한다.

재계산 하는 경우 원본 데이터를 사용하고 집계 서비스를 재사용해 추가 로직 관리 비용을 없애야 한다.
집계 단위
책에서는 타임스탬프를 기준으로 집계를 진행하게 되는데 이벤트 시각과 처리 시각 중 하나의 데이터를 단위로 선정해야 한다. 어떤 단위로 선정하느냐에 따라 제공하는 서비스가 달라진다.
| 장점 | 단점 | |
|---|---|---|
| 이벤트 발생 시각 | 시간대에 맞게 정확한 집계 결과 확인 가능 | 클라이언트 결과에 의존하므로 클라이언트 시각 오류나 조작으로 인한 문제 발생 |
| 처리 시각 | 이벤트 발생 시각보다 안정적 | 이벤트 발생과 처리 간의 지연이 발생하면 한 순간 부정확해지게 됨 |
각 장단점을 고려해 단위를 결정해야 하는데 정확도가 중요하면 이벤트 발생 시각을 기준으로 집계한다. 이벤트 발생 시각을 사용할 경우 지연 처리 해결 방법으로 워터마크를 사용한다.
윈도를 기준으로 집계하면 다음처럼 일정 시간 동안 데이터를 수집하게 된다. 만약 ASIS처럼 데이터가 늦게 들어오면 정확한 데이터 처리가 어려워지기 때문에 여분을 추가로 둔 워터마크를 이용해 정확도를 높인다.
| ASIS | TOBE |
|---|---|
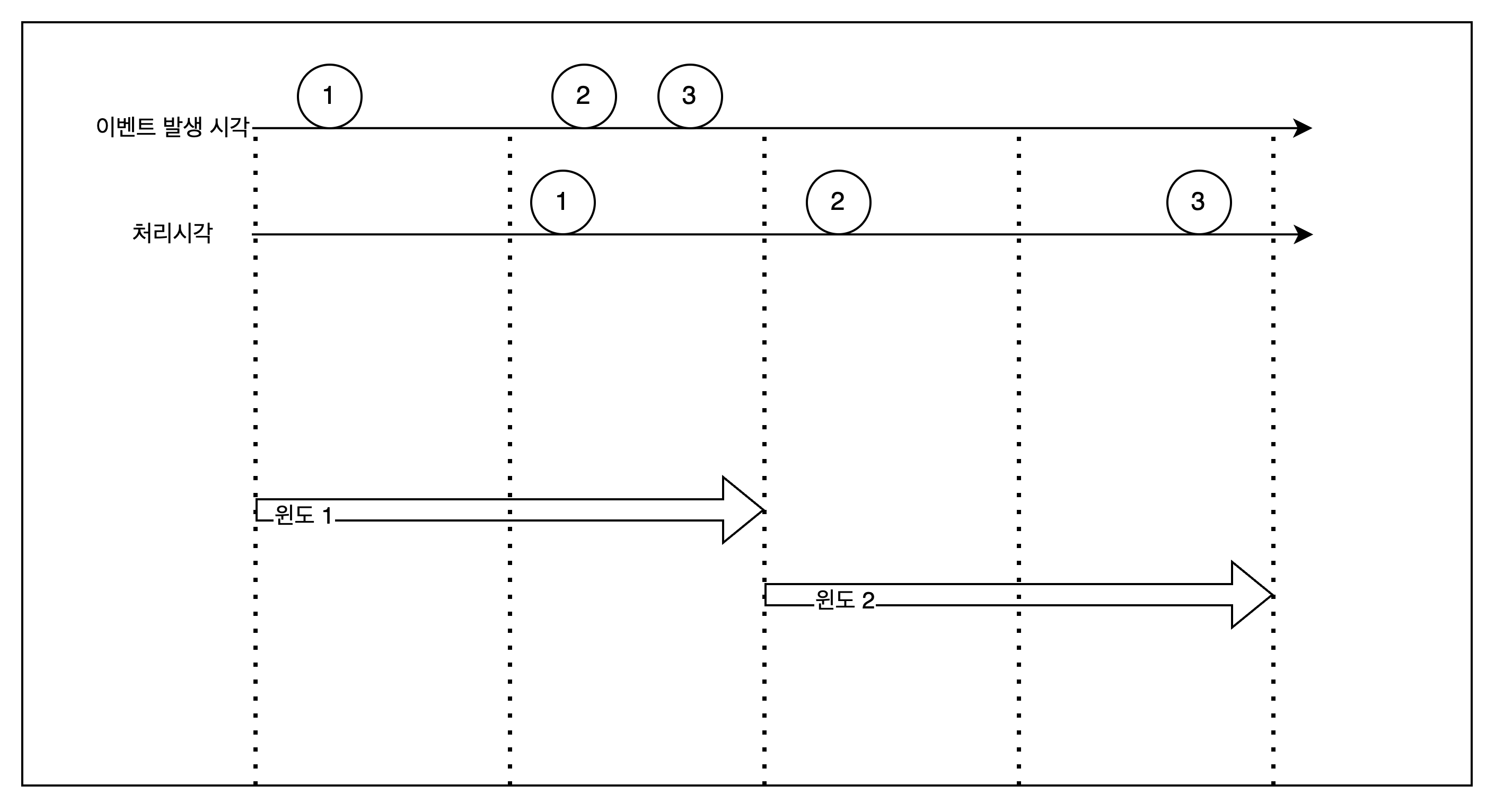 | 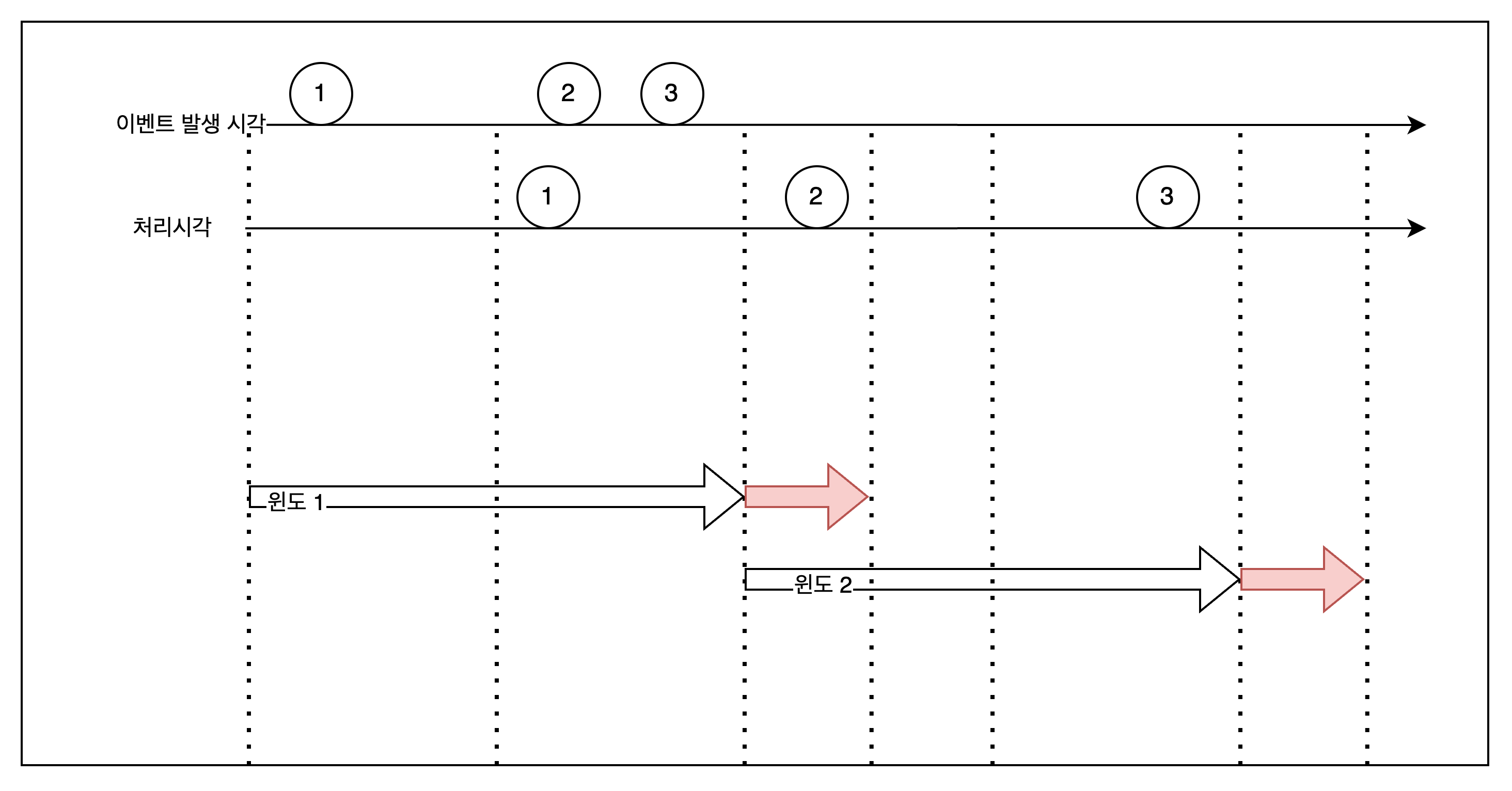 |
도메인 특성에 따라 워터마크(여분 윈도 사이즈) 길이가 결정된다. 워터마크가 길수록 지연 시간이 길어지니 주의해야 한다.
윈도를 이용한 집계 방식은 다음과 같다.
- 텀블링 윈도 : 그룹 단위 집계 방식
- 호핑 윈도 : 텀블링 윈도우와 달리 그룹을 겹쳐 집계하는 방식
- 슬라이딩 윈도 : 윈도 크기가 일정하게 유지되어 시간 경과에 따라 집계 영역이 달라지는 방식
- 세션 윈도 : 데이터가 들어온 시간의 유사성으로 그룹화한 방식
- 스태거 윈도 : 고정된 시간 단위로 결과를 집계하는 방식
집계 무결성 보장
카프카와 같은 메시지 큐는 최대 한 번(at-most-noe), 최소 한 번(at-least-once), 정확히 한 번(exactly-once) 유형 중 한 가지를 지원한다.
약간의 중복이 괜찮다면 최소 한 번(at-least-once)을 활용하는 등 상황에 맞게 선택한다..
오프셋을 알리기 위해서 응답을 보낼 때 장애가 발생하면 중복 처리가 발생할 수 있기 때문에 외부 저장소에 오프셋을 기록하며 관리 할 수 있다.
| ASIS | TOBE |
|---|---|
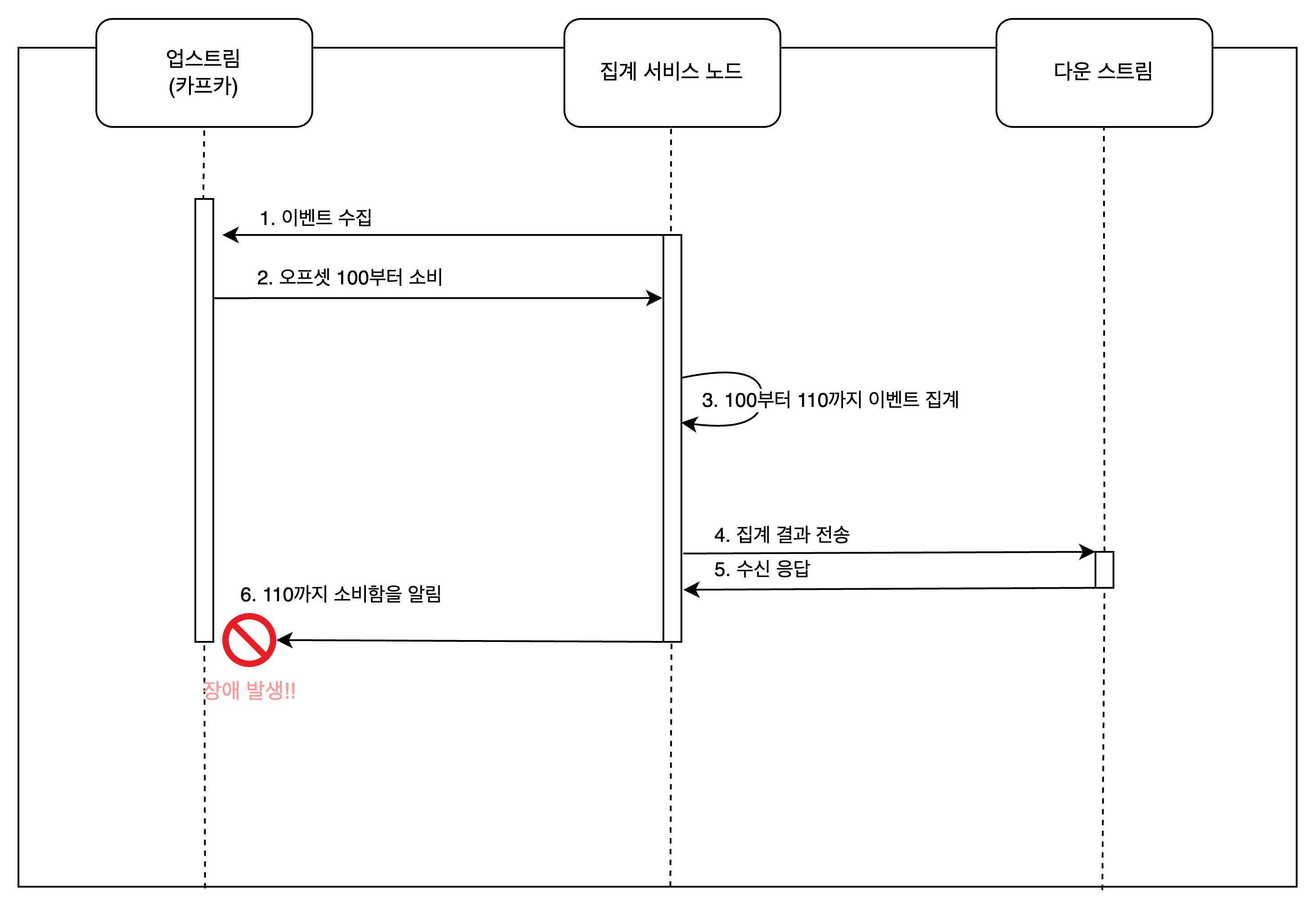 | 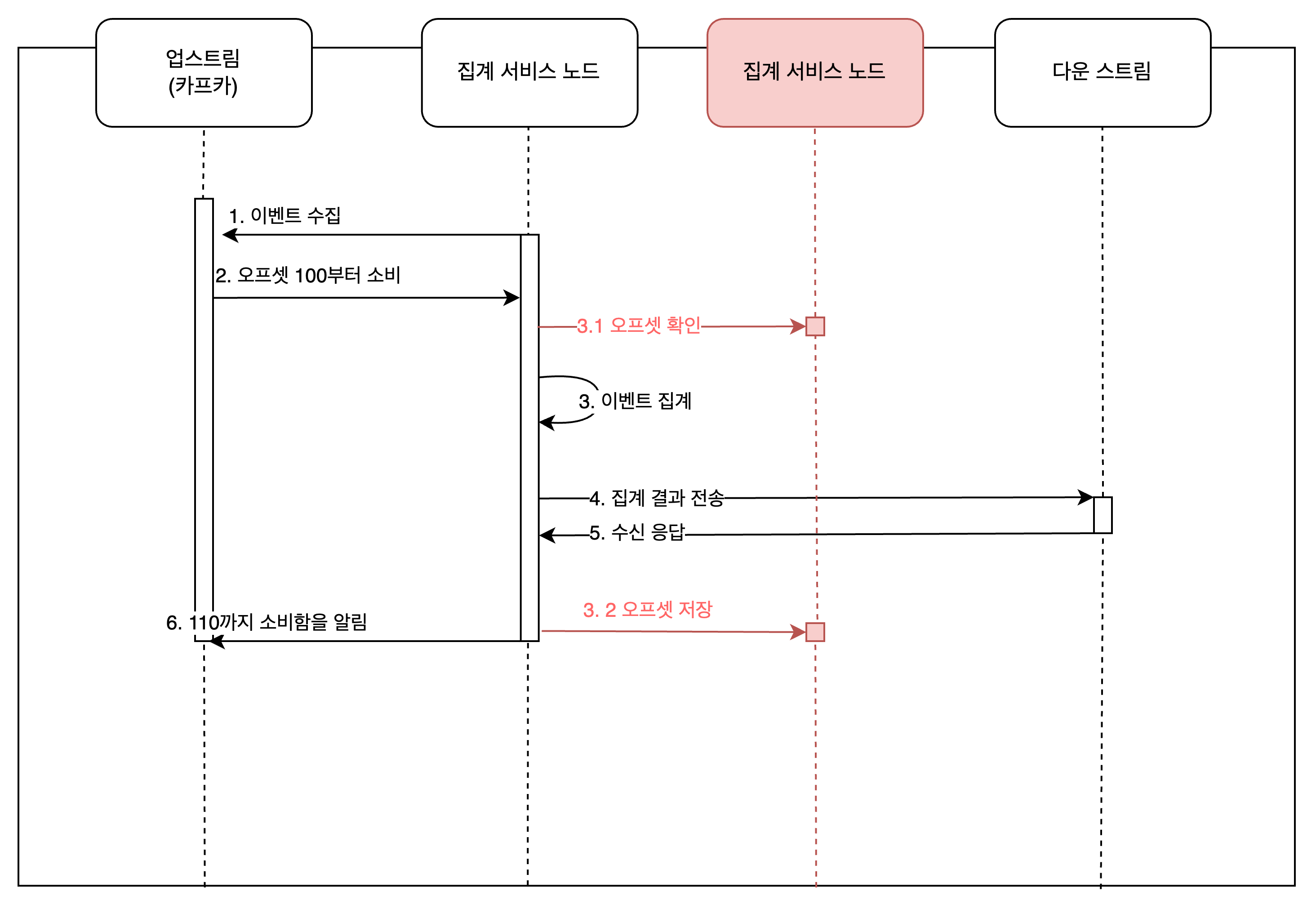 |
무결성을 보장하기 위해서는 트랜잭션 단위와 롤백할 영역을 잘 고민해야 한다. 다음 처럼 분산 트랜잭션을 이용해 더 높은 무결성을 보장할 수 있다.

집계 서비스 규모 확장
집계 서비스 처리 대역폭을 높이기 위해 노드 수평 조정이 필요하다. 처리 대역폭을 관리하는 방법은 두 가지가 존재한다.
- 식별자 기준으로 별도의 처리 스레드를 둔다.
- 자원 공급자(YARN)로 멀티 프로세싱을 활용한다.
첫 번째가 구현하기 쉽지만 컴퓨팅 자원 추가가 쉬운건 두 번째다. 확장성을 고려해서 결정하면 되겠다.
데이터베이스 규모 확장 - 핫스팟 문제
광고 클릭 이벤트를 수신할 때 특정 광고만 수신하게 된다면 과부하 문제가 발생한다. 이런 핫스팟 문제는 집계 서비스 노드를 할당하여 완화할 수 있다.
- 집계 서비스에 대량에 이벤트가 도착해 하나의 노드가 감당할 수 없게 된다.
- 집계 서비스는 자원 관리자에게 추가 자원을 신청한다.
- 노드에 과부하가 걸리지 않도록 추가 자원을 할당한다.
위 방법을 사용하거나 전역-지역 집계(Global-Local Aggregation)이나 분할 고유 집계(Split Distinct Aggregation) 같은 방안이 있다.
4 단계 : 마무리
배치
배치처리 할 때 작업을 비순환 그래프 형식으로 구성한다면 쉽게 튜닝할 수 있다. map -> reduce로도 튜닝할 수 있고, 병렬 처리로도 튜닝이 가능하다.
정확성과 무결성 고민
데이터 정확성과 무결성을 고민할 떄는 다음 질문을 생각한다.
- 이벤트 중복 처리는 어떻게 피할까?
- 모든 이벤트를 처리한 다는 걸 어떻게 보장할까?