- Published on
비결정적 특징에 대한 개인적인 정리
- Authors

- Name
- 이건창
Introduction
자바 메모리 모델과 관련 이슈를 학습해보려고 한다.
비걸정적 특성과 동기화
우리가 작성한 코드는 우리 고려대로 동작하지 않고 다음 이슈가 있다.
- 운영 체제로 인해 스레드 실행 순서가 달라질 수 있다.
- 메모리 모델로 인해 명령어 순서가 달라질 수 있다.
작성한 코드가 여러 스레드로 실행되면서 동시성을 얻게되고 그렇게 비결정적 특성을 가지게 된다. 각 이슈가 어떤 문제를 낳고 어떻게 해결하는지 파악해보겠다.
스레드 실행 순서가 변경되면서 발생하는 문제
동시성과 병렬성이 혼동되는 이유는 전통적인 스레드와 장금장치는 병렬성을 직접 지원하지 않기 때문이다. 병렬 프로그램에서 동시성을 만족하기 어려운 이유는 동시성은 비결정성(nondeterministic) 특징을 가지고 병렬성은 비결정성(nondeterministic)을 가지지 않기 때문이다.
비결정적(
nondeterministic) 특징 : 사건이 일어나는 시간에 따라 결과가 달라지는 특성이다. 동시성은 타이밍에 따라 결과가 달라질 수 있지만 병렬성은 의도한 결과가 나와야 한다.
직상힌 코드
입금, 출금, 이체 로직은 다음과 같다.
class Deposit(
private val user: User,
private val money: Money,
) {
fun execute1() {
user.balance += money
}
}
class Transfer(
private val source: User,
private val target: User,
private val money: Money,
) {
fun execute() {
source.balance -= money
target.balance += money
}
}
class Withdraw(
private val user: User,
private val money: Money,
) {
fun execute() {
user.balance -= money
}
}
비결정적 특성으로 인한 문제
동시성은 비결정성 특징을 가져 결과가 달라진다. 다음은 비결정성으로 의도한 결과가 나오지 않는 경우다.
@RepeatedTest(100)
fun codeTest1Fail() {
val user1 = User("user1")
val user2 = User("user2")
val threadPool = CustomThreadPool()
val iteration = 100
for (i in 1..iteration) {
threadPool.submit { Deposit(user1, Money(100)).execute1() }
threadPool.submit { Deposit(user2, Money(100)).execute1() }
threadPool.submit { Withdraw(user2, Money(100)).execute1() }
threadPool.submit { Transfer(user1, user2, Money(50)).execute1() }
}
threadPool.runAll()
threadPool.joinAll()
assertEquals(100 * iteration - 50 * iteration, user1.balance.amount)
assertEquals(50 * iteration, user1.balance.amount)
}
비결정적 특성으로 인한 문제 해결 1 - 명령어 순차적으로 처리
비결정성 특징을 제거하기 위해 동기화한다. 동기화 방법으로 명령어를 순차적으로 실행한다. 그러나 동기화 컨텍스트가 넓어질 수록 동시성이 떨어진다.
analytics: {
@RepeatedTest(100)
fun codeTest1Fail() {
val user1 = User("user1")
val user2 = User("user2")
val threadPool = CustomThreadPool()
val iteration = 100
for (i in 1..iteration) {
- threadPool.submit { Deposit(user1, Money(100)).execute1() }
- threadPool.submit { Deposit(user2, Money(100)).execute1() }
- threadPool.submit { Withdraw(user2, Money(100)).execute1() }
- threadPool.submit { Transfer(user1, user2, Money(50)).execute1() }
+ threadPool.submit { synchronized(this) { Deposit(user1, Money(100)).execute1() } }
+ threadPool.submit { synchronized(this) { Deposit(user2, Money(100)).execute1() } }
+ threadPool.submit { synchronized(this) { Withdraw(user2, Money(100)).execute1() } }
+ threadPool.submit { synchronized(this) { Transfer(user1, user2, Money(50)).execute1() } }
}
threadPool.runAll()
threadPool.joinAll()
assertEquals(100 * iteration - 50 * iteration, user1.balance.amount)
assertEquals(50 * iteration, user1.balance.amount)
}
},
간단하게 synchronized 를 사용한 바이트 코드에서는 MONITORENTER 와 MONITOREXIT를 이용해 동기화를 수행한다.
public final execute2()V
TRYCATCHBLOCK L0 L1 L2 null
TRYCATCHBLOCK L2 L3 L2 null
L4
LINENUMBER 12 L4
ALOAD 0
GETFIELD tis/Withdraw.user : Ltis/User;
ASTORE 1
ALOAD 1
MONITORENTER <<-- 모니터락 획득
// 생략 ...
L1
ALOAD 1
MONITOREXIT <<-- 정상 처리인 경우 모니터락 해제
GOTO L9
L2
FRAME FULL [tis/Withdraw tis/User] [java/lang/Throwable]
ASTORE 2
L3
ALOAD 1
MONITOREXIT <<-- 예외인 경우 모니터락 해제
ALOAD 2
ATHROW
// 생략 ...
L10
LOCALVARIABLE $i$a$-synchronized-Withdraw$execute2$1 I L5 L7 2
LOCALVARIABLE this Ltis/Withdraw; L4 L10 0
MAXSTACK = 3
MAXLOCALS = 4
비결정적 특성으로 인한 문제 해결 1 - 동기화 영역을 좁힌다.
동기화 컨텍스트를 좁혀 리소스 사용량을 높였다. 이 때 사용자 객체를 기준으로 동기화한다.
class Deposit(
private val user: User,
private val money: Money,
) {
fun execute1() {
+ synchronized(user) {
user.balance += money
+ }
}
}
class Transfer(
private val source: User,
private val target: User,
private val money: Money,
) {
fun execute() {
+ synchronized(source) {
+ synchronized(target) {
source.balance -= money
target.balance += money
+ }
+ }
}
}
class Withdraw(
private val user: User,
private val money: Money,
) {
fun execute() {
+ synchronized(user) {
user.balance -= money
+ }
}
}
데드락 발생 문제
사용자를 기준으로 동기화를 진행하는 경우 데드락 발생하게 된다.
@Test
fun codeTest3Fail() {
val user1 = User("user1")
val user2 = User("user2")
val user3 = User("user3")
val user4 = User("user4")
val user5 = User("user1")
val threadPool = CustomThreadPool()
val listOf = listOf(user1, user2, user3, user4, user5)
listOf.forEach {
Deposit(it, Money(100)).execute1()
}
for (i in 1..100) {
threadPool.submit { Transfer(user1, user2, Money(100)).execute() }
threadPool.submit { Transfer(user2, user3, Money(100)).execute() }
threadPool.submit { Transfer(user3, user4, Money(100)).execute() }
threadPool.submit { Transfer(user4, user5, Money(100)).execute() }
threadPool.submit { Transfer(user5, user1, Money(100)).execute() }
}
threadPool.runAll()
threadPool.joinAll()
listOf.forEach {
assertEquals(100, it.balance.amount)
}
}
데드락 발생 문제 해결 - 원형 의존성을 제거한다.
데드락은 동기화 순서를 순차적으로 수행하는 경우 해결할 수 있다. 잠금 장치 획득 순서가 원형적인 형태이면 데드락이 발생하고 그렇지 않다면 발생하지 않는다.
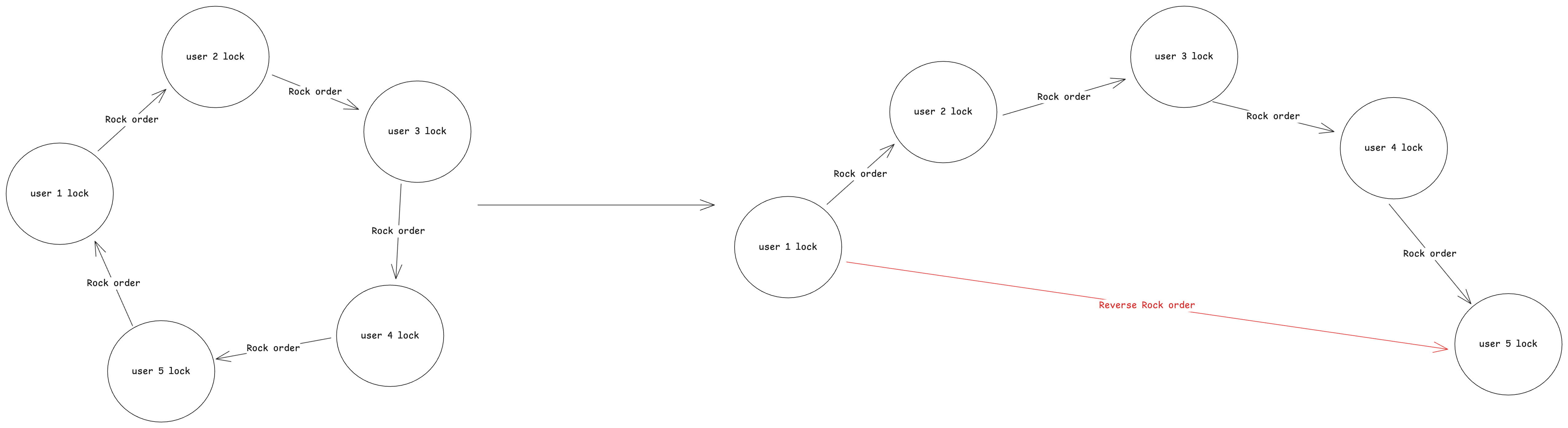
즉, 사용자를 정렬할 수 있다면 락 획득에 순서를 정의해 문제를 해결할 수 있다.
class Transfer(
private val source: User,
private val target: User,
private val money: Money,
) {
- fun execute() {
- synchronized(source) {
- synchronized(target) {
- source.balance -= money
- target.balance += money
- }
- }
- }
+ fun execute() {
+ return if (source < target) {
+ synchronized(source) {
+ synchronized(target) {
+ source.balance -= money
+ target.balance += money
+ }
+ }
+ } else {
+ synchronized(target) {
+ synchronized(source) {
+ source.balance -= money
+ target.balance += money
+ }
+ }
+ }
+ }
}
고민할 내용 - 외부 메서드를 호출하는가?
동기화를 통해 비결정적 특성을 추출할 수 있었다. 그러나 동기화된 코드에서 외부 메서드를 호출하게 된다면 외부에서는 어떤 동작을 하는지 파악하기 어려워진다. 관리에서 벗어나게 되면 새로운 데드락의 가능성이 될 수도 있기에 외부 메서드 호출을 자제해야 한다.
데이터 영속화까지 진행되는 과정에서 내제된 잠금장치를 이용해 동기화를 하는건 어려운 방법일 수 있지만 외부 메서드 호출을 제외하고 동기화를 진행하는 방법을 고민해보자.
메모리 모델로 인해 명령어 순서가 달라지는 문제
명령어 순서는 자바 메모리 모델에서 결정한다. 다음 코드를 예시로 확인해보겠다.
public class Main2 {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
private static long reorders = 0;
private static final int ITERATIONS = 1_000_000;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < ITERATIONS; i++) {
x = y = a = b = 0;
Thread t1 = new Thread(() -> {
a = 1;
x = b;
});
Thread t2 = new Thread(() -> {
b = 1;
y = a;
});
t1.start();
t2.start();
t1.join();
t2.join();
if (x == 0 && y == 0) {
reorders++;
}
}
System.out.println("Reorders detected: " + reorders);
}
}
대략 세 개의 케이스로 볼 수 있는데, 기대할 수 있는 값은 (1, 0), (0, 1), (1, 1)인데, (0, 0) 결과가 발생했다. 컨텍스트 스위칭으로 명령어 실행 과정이 변경되도 발생할 수 었는 문제다.
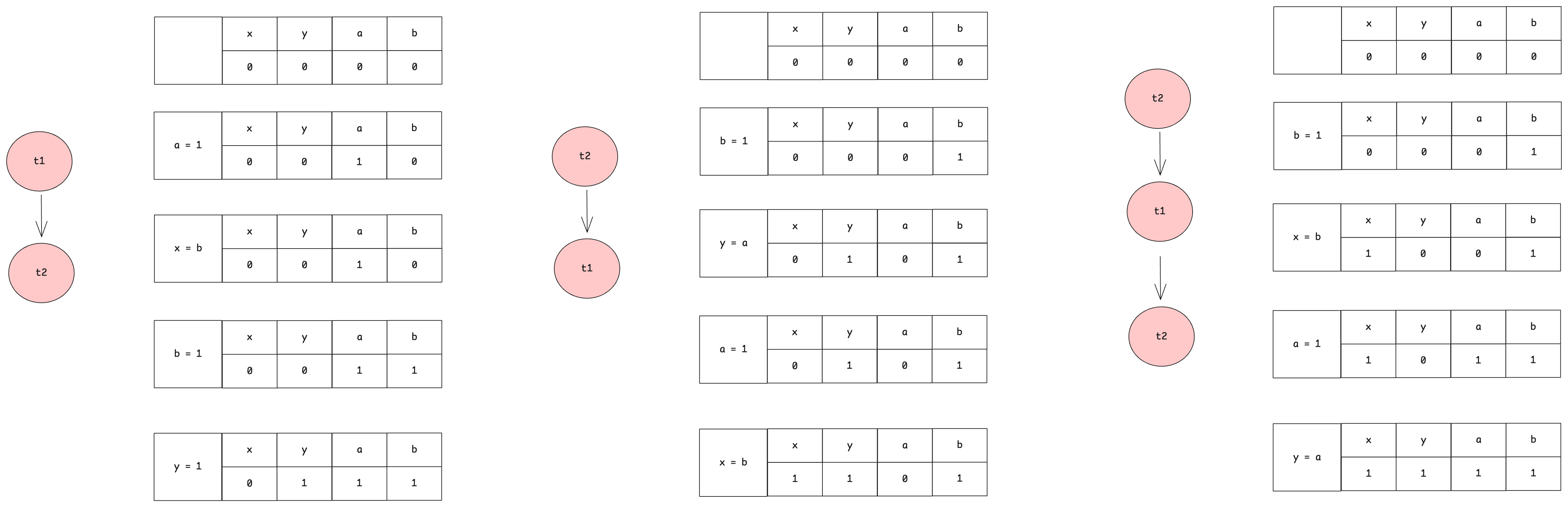
이 상황은 데이터 경쟁으로 직관적이지 않은 결과가 발생했고, 부적절하게 동기화가 됐음을 이해할 수 있다. 대략적으로 다음처럼 정리할 수 있다.
t1 또는 t2 중 하나가 명령어 순서가 변경됐다. 그래서 읽으려는 스레드가 아직 써지지 않은 스레드에 접근했다.
컴파일 과정으로 명령어가 변경되는 상황처럼 읽는 과정은 구현한 메모리 모델에 의존하게 된다. 즉, 격리된 각 스레드 동작은 해당 스레드 의미론에 따라 동작하지만 값 읽는 방법은 메모리 모델에서 결정한다.
이런 경우 메모리 베리어를 사용해 해결하기도 한다. 메모리 베리어는 비순차적 실행을 초래하는 경우 사용한다. 정렬 제약 조건은 하드웨어에 따라 달라지며 메모리 정렬 모델로 결정된다.
실행엔진 확인
명령어가 어떤 상황에서 순서가 변경되는지 파악해보자. JVM은 클래스 파일을 실행 엔진에서 기계어로 변환하게 된다. 기계어로 변환하는 방식은 두 가지다.
- 인터프리터 : 바이트코드를 한 줄 씩 읽고 실행
- JIT 컴파일러 : 자주 사용되는 코드를 네이티브 코드로 컴파일해 저장
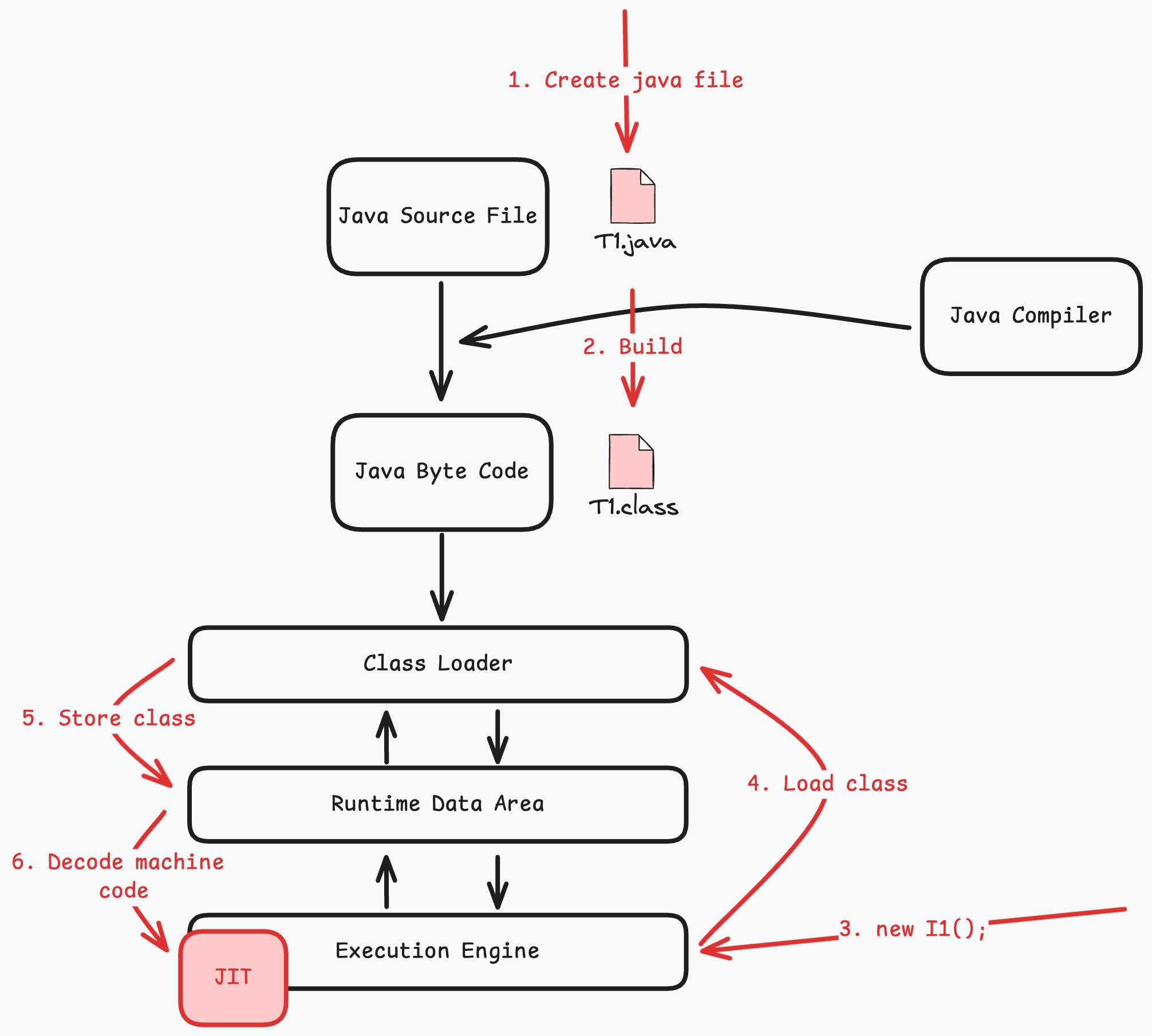
인터프리터에 의해 기계어를 동적으로 생성하면 명령어 순서가 계속해서 바뀌는 모습을 볼 수 있다. 그러나 JIT 컴파일러가 트리거되면 더 이상 볼 수 없다. JIT 컴파일러는 사전에 정의된 컴파일 임계값을 넘기면 JIT 컴파일이 트리거 된다.
JIT (Just-In-Time) 컴파일러는 바이트코드 시퀀스로 기계어를 동적으로 생성한다. JIT 컴파일러는 명령어를 최적화해 더 나은 하드웨어 사용성을 제공한다.
즉, 초기에 인터프리터에 의해 동적으로 생성되는 순간이 아니면 JIT 컴파일러를 이용해 기계어로 컴파일하고 결과를 캐싱하고 있다. JIT 동작 과정은 다음과 같다.
- 인라이닝 : 외부 메서드 호출할 때 외부 메서드 내용을 가져와 실제 코드로 치환하는 작업이다.
- 로컬 최적화 : 코드 섹션을 분석해 개선한다.
- 제어 플로우 최적화 : 제어 플로우블 분석하고 코드 경로를 재배열 한다.
- 글로벌 최적화 : 전체 코드를 검사하고 일부 중복을 제거하고 동기화를 최적화한다.
- 원시 코드 생성 : 기계어를 생성한다.
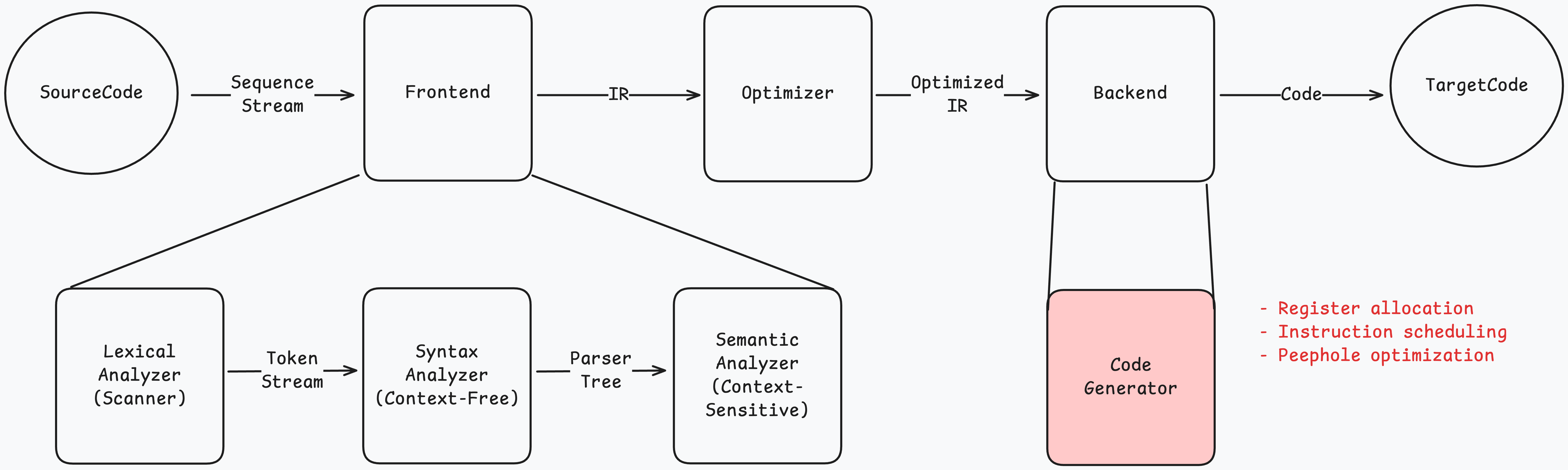
일반적인 컴파일러 구조
컴파일러 일반적인 구조를 확인해서 JIT 컴파일러 동작을 예측할 수 있어보인다. 컴파일러 개론에 작성된 내용은 다음과같다.
Frontend 영역에서 작성된 코드를 분석하고 IR 이라는 AST 트리로 변환해 Optimizer로 전달한다. Optimizer는 코드를 최적화해 Backend로 전달한다. Backend는 운영체제가 이해할 수 있는 코드로 변환한다.
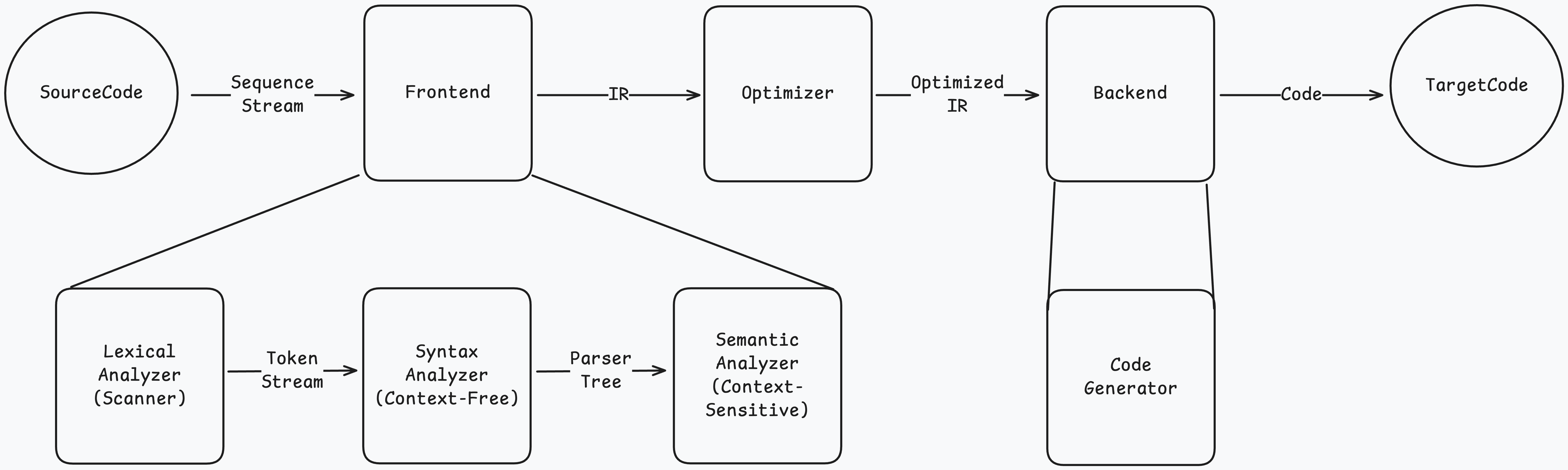
이 때 각각의 최적화 방법이 존재하지만 명령어 순서가 변경되는 영역은 Backend 영역의 Code Generator 때문이다. Code Generator는 다음과 같은 동작을 한다.
- Register allocation : 레지스터 할당을 최소화하기 위해 명령어를 재배치한다.
- Instruction scheduling : 명령어 파이프라이닝에 최적화하기 위해 명령어를 재배치한다.
- Peephole optimization : 틈새(peephole)를 줄이기 위해 명령어를 최적화한다.
틈새(peephole)를 줄이는 건 다음 과정으로 이루어진다.
- Redundant load and store elimination : 중복 읽기와 쓰기를 줄인다.
- Constant folding : 상수를 미리 계산한다.
- Strength Reduction : 연산 강도 감소
Redundant load and store elimination
- y = x + 5;
- i = y;
- z = i;
- w = z * 3;
+ y = x + 5;
+ w = y * 3;
Constant folding
- y = 3 + 5;
+ y = 8;
Strength Reduction
AS-IS
- y = x * 2;
+ y = x << 1; // or y = x + x;
순서 변경에 대해서 정리하자면
정리하자면 자바 메모리 모델은 독립된 스레드 실행에 영향을 미치지 않는다면 명령어는 재정렬을 허용한다. 일반적인 컴파일러는 독립된 스레드 실행에 영향을 미치지 않는다면 명령어는 재정렬된다. 그래서 각 스레드는 명령어가 재정렬된다. JVM은 인터프리터로 실행될때마다 명령어 순서를 결정하지만 JIT 설정한 실행 횟수 임계치를 넘으면 컴파일 결과를 캐싱해 재활용한다. 그럼 명령어 순서가 변경되는 상황은 지극히 드물다.