- Published on
elastic 8 apm 설정 과정
- Authors

- Name
- 이건창
Introduction
- 개요
- Self-hosted apm server
- Self-hosted apm server 트러블 슈팅 1 - precondition failed: error querying cluster_uuid: status_code=401
- Self-hosted apm server 트러블 슈팅 2 - precondition 'apm integration installed'
- Self-hosted apm server 트러블 슈팅 3 - The APM integration must be upgraded.
- Fleet managed apm server
- Fleet managed apm server 트러블 슈팅 1 : publish ready false
- Fleet managed apm server 트러블 슈팅 2 : agnet가 추가 안돼요!
- Apm agent의 가능성
- 클라이언트에서 에이전트 등록
- 클라이언트에서 에이전트 등록 트러블 슈팅 1 - Route Unkown
- 운영환경 이슈 트러블 슈팅 1 - Data too large
- 운영환경 이슈 트러블 슈팅 2 - 늘어나는 데이터셋
- 운영환경 이슈 트러블 슈팅 3 - Spring cloud gateway 추적 불가 이슈
개요
사내에서 apm 을 self-hosted 해야 하는 상황이었고 개인적으로 테스트를 진행했다. 운영 환경에서 실행되는 elasticsearch는 8.14여서 8.14 에 맞게 테스트했다. apm 을 설정하려면 우선 apm server를 가용할지 elastic agent를 가용할지 고민해야 한다.
- apm-server 사용 : 7.X 버전 이하에서 사용하는 방식이다. 8.X 버전부터는 APM integration을 설정해 인식할 수 있도록 구성해야 한다.
- elastic-agent 사용 : agent 가 apm server를 관리한다. 별개로 다양한 기능을 제공한다.
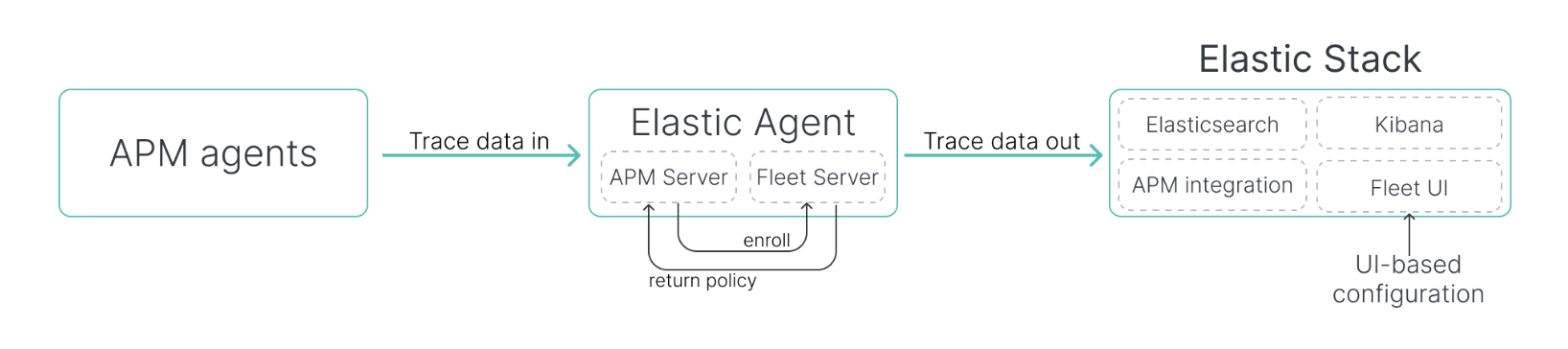
어떤 방식을 사용할지는 다음 의사 결정 모델로 결정하면 된다. 필자는 RUM을 사용하면서 다른 통합 기능을 사용할거기에 중앙에서 관리되는 agent 툴을 사용할 생각이다.
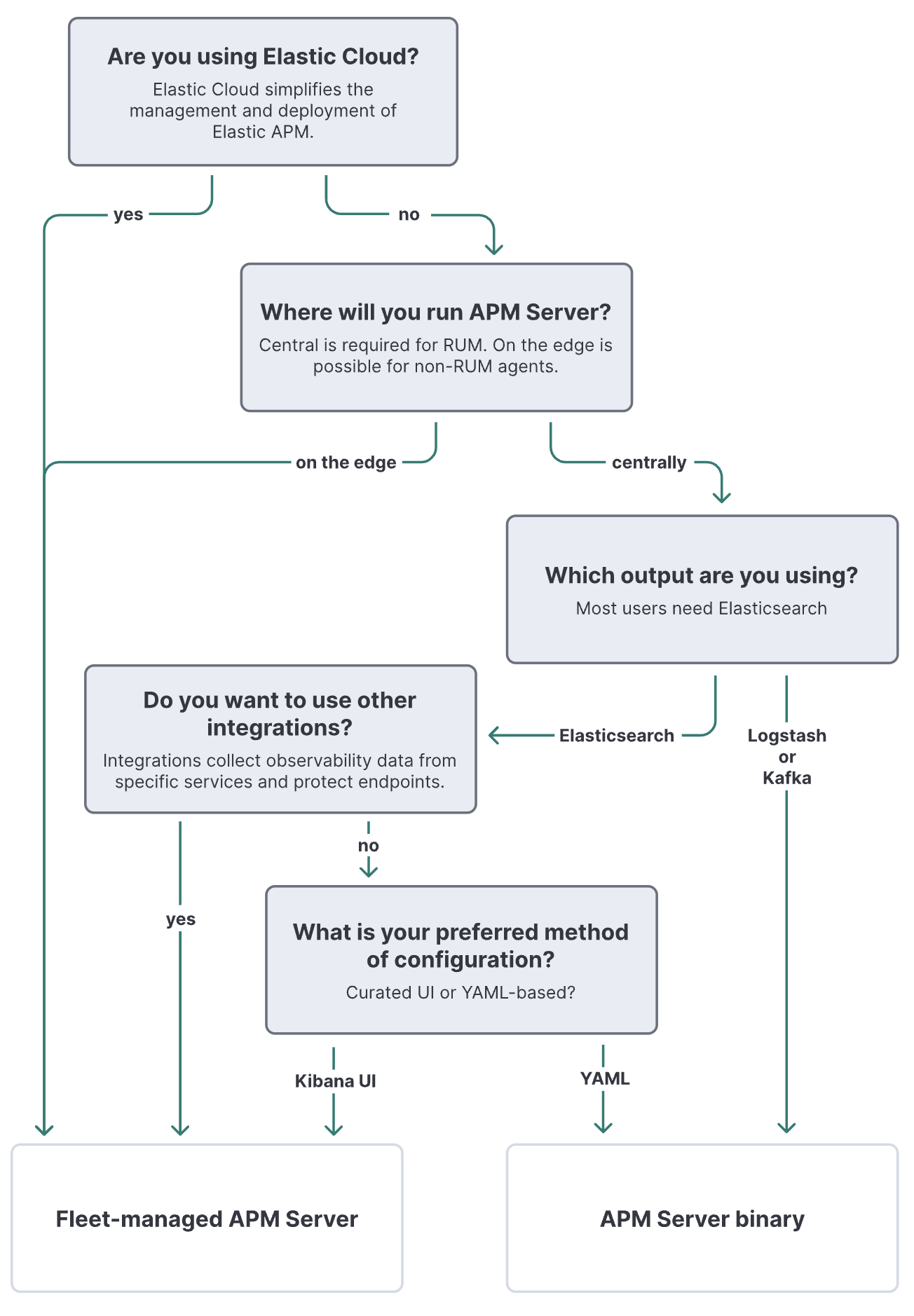
하지만 이번 기회에 여러 방면으로 실행 가능한지 테스트해보기 위해 apm server 부터 테스트했다.
Self-hosted apm server
Agent Policy APM Server 에 설정된 버전에 맞게 apm server를 설치한다. 필자는 8.11.3에 맞게 설치했다.
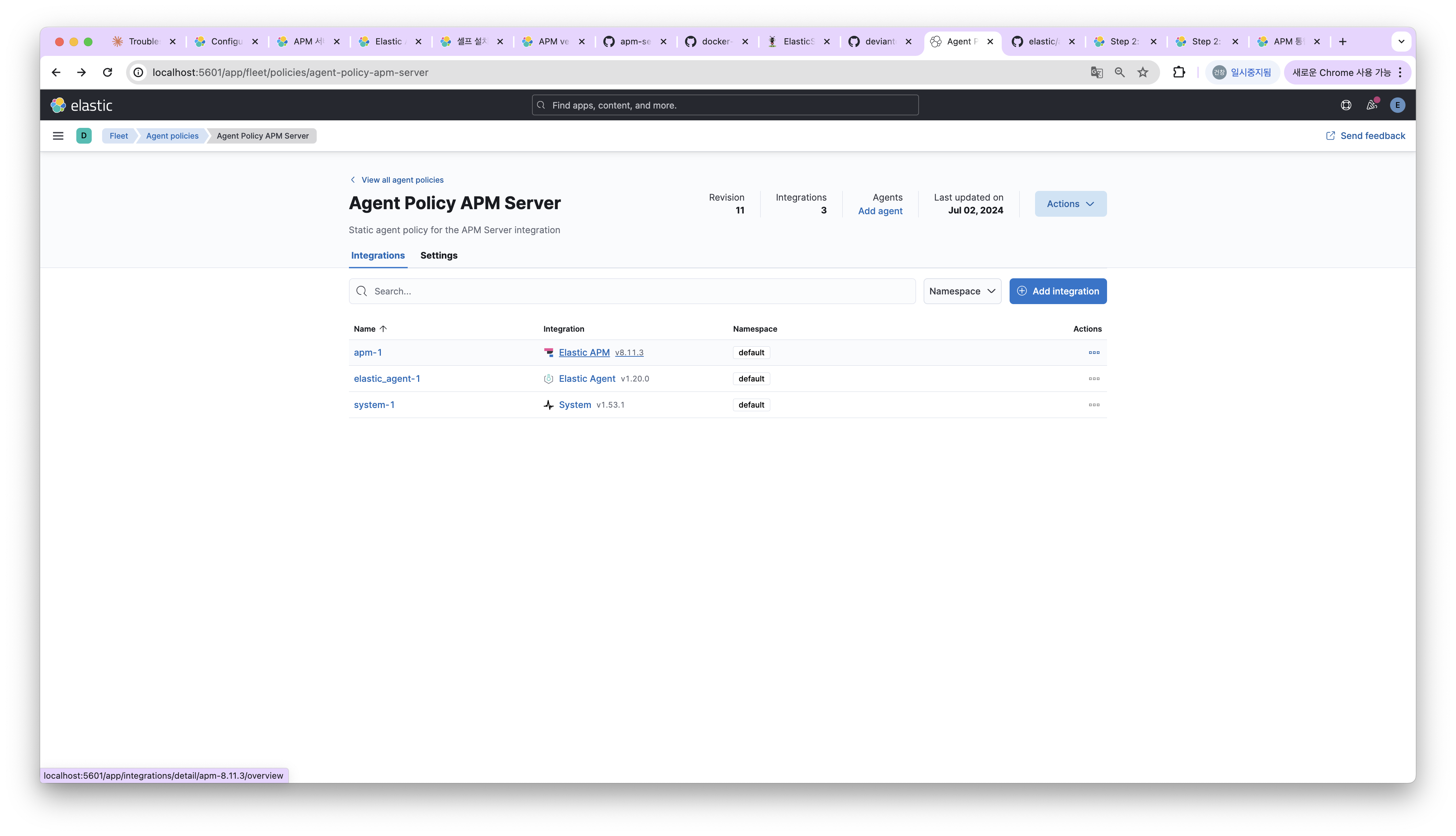
다음처럼 설치한 후에 디렉토리에 존재하는 apm-server.yml 를 수정해야 한다.
curl -L -O https://artifacts.elastic.co/downloads/apm-server/apm-server-8.11.3-darwin-x86_64.tar.gz
tar xzvf apm-server-8.11.3-darwin-x86_64.tar.gz
cd apm-server-8.11.3-darwin-x86_64
apm-server.yml에서 수정할 부분은 다음과 같다.
- apm-server.host
- output.elasticsearch.hosts
- output.elasticsearch.username
- output.elasticsearch.password
output.elasticsearch.hosts 값은 배열 형식으로 작성해야 하니 주의하자.
######################### APM Server Configuration #########################
################################ APM Server ################################
apm-server:
# Defines the host and port the server is listening on. Use "unix:/path/to.sock" to listen on a unix domain socket.
host: "127.0.0.1:8200"
#================================ Outputs =================================
# Configure the output to use when sending the data collected by apm-server.
#-------------------------- Elasticsearch output --------------------------
output.elasticsearch:
# Array of hosts to connect to.
# Scheme and port can be left out and will be set to the default (`http` and `9200`).
# In case you specify and additional path, the scheme is required: `http://localhost:9200/path`.
# IPv6 addresses should always be defined as: `https://[2001:db8::1]:9200`.
hosts: ["localhost:9200"]
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
username: "elastic"
password: "pass"
설정을 완료했다면 apm server를 실행하면 완료다. 이제는 실행 후 로그를 살펴보면서 연결됐는지 확인해야 한다.
./apm-server -e
정상 실행됐는지 확인하기 위해서 apm server로 GET / 요청을 보내면 된다. publish_ready가 true면 요청 받을 준비가 된 것이다.
curl http://localhost:8200
{
"build_date": "2023-12-07T11:11:14-05:00",
"build_sha": "cba21e88bd0d376ec77dc77fccccfdc0c27206ac",
"publish_ready": true,
"version": "8.11.3"
}
Self-hosted apm server 트러블 슈팅 1 - precondition failed: error querying cluster_uuid: status_code=401
인증이 정상적으로 이루어지지 않았을 때 발생하며 username, password 또는 api key가 정상인지 확인해야 한다.
{
"log.level":"error",
"@timestamp":"2024-06-30T22:13:11.224Z",
"log.logger":"beater",
"log.origin":{"file.name":"beater/waitready.go","file.line":64},
"message":"precondition failed: error querying cluster_uuid: status_code=401",
"service.name":"apm-server",
"ecs.version":"1.6.0"
}
api key를 사용한다면 id:api_key 형식으로 등록해야 하며 elasticsearch 에서 xpack.security.authc.api_key.enabled가 true로 설정되어야 한다. (기본값 true)
발급 방식은 다음처럼 유효기간과 함께 사용할 수 있는 권한을 한정하면 된다.
curl -X POST -u elastic:password "localhost:9200/_security/api_key?pretty" -H 'Content-Type: application/json' -d'
{
"name": "my-api-key",
"expiration": "1d",
"role_descriptors": {
"apm_writer": {
"index": [
{
"names": ["apm-*"],
"privileges": ["create_index", "create_doc"]
}
]
},
"apm_sourcemap": {
"index": [
{
"names": [".apm-source-map"],
"privileges": ["read"]
}
]
},
"apm_agentcfg": {
"index": [
{
"names": [".apm-agent-configuration"],
"privileges": ["read"]
}
]
}
},
"metadata": {
"application": "my-application",
"environment": {
"level": 1,
"trusted": true,
"tags": ["dev", "staging"]
}
}
}
'
api key 관련해서는 해당 글을 참고하자. 그럼 다음처럼 발급받을 수 있다.
{
"id" : "PBt_c5ABPp00qxZHzw2z",
"name" : "my-api-key",
"expiration" : 1720011074501,
"api_key" : "Ho03mwqqQ3mLYfDAYjOiQg",
"encoded" : "UEJ0X2M1QUJQcDAwcXhaSHp3Mno6SG8wM213cXFRM21MWWZEQVlqT2lRZw=="
}
이 때 주의할 점은 output.elasticsearch.api_key 설정 값에는 id:api_key 형식으로 작성해야 한다는 점이다. 즉 위 정보로 조합했을 때PBt_c5ABPp00qxZHzw2z:Ho03mwqqQ3mLYfDAYjOiQg 값이 추가되어야 한다.
간단하게 테스트하고 싶다면 사용자 정보로 실행하면 되지만 운영 환경에서 사용자 정보 공유는 부담스럽다. 그런 상황은 해당 방식을 사용하자.
Self-hosted apm server 트러블 슈팅 2 - precondition 'apm integration installed'
apm integration 설정을 하지 않고 apm에 연결하려 한다면 다음과 같은 예외가 발생한다. 만약 설정되지 않았다면 fleet → agent policies 에서 apm integration을 추가한다.
{
"log.level":"error",
"@timestamp":"2024-07-01T00:58:10.258Z",
"log.logger":"beater",
"log.origin":{"function":"github.com/elastic/apm-server/internal/beater.waitReady","file.name":"beater/waitready.go","file.line":62},
"message":"precondition 'apm integration installed' failed: error querying Elasticsearch for integration index templates: unexpected HTTP status: 404 Not Found ({\"error\":{\"root_cause\":[{\"type\":\"resource_not_found_exception\",\"reason\":\"index template matching [logs-apm.error] not found\"}],\"type\":\"resource_not_found_exception\",\"reason\":\"index template matching [logs-apm.error] not found\"},\"status\":404}): to remediate, please install the apm integration: https://ela.st/apm-integration-quickstart",
"service.name":"apm-server",
"ecs.version":"1.6.0"
}
여기에서 혼동하지 말아야할 점은 agent를 추가하지 않아도 실행되니 agent 설치하는 과정으로 넘어가지 않도록 주의해야 한다.
사실 해당 이슈는 만날 일이 없다. 8.14를 처음 설치하게 되면 apm policy인 **Agent Policy APM Server**를 기본으로 설정해주기 때문이다.
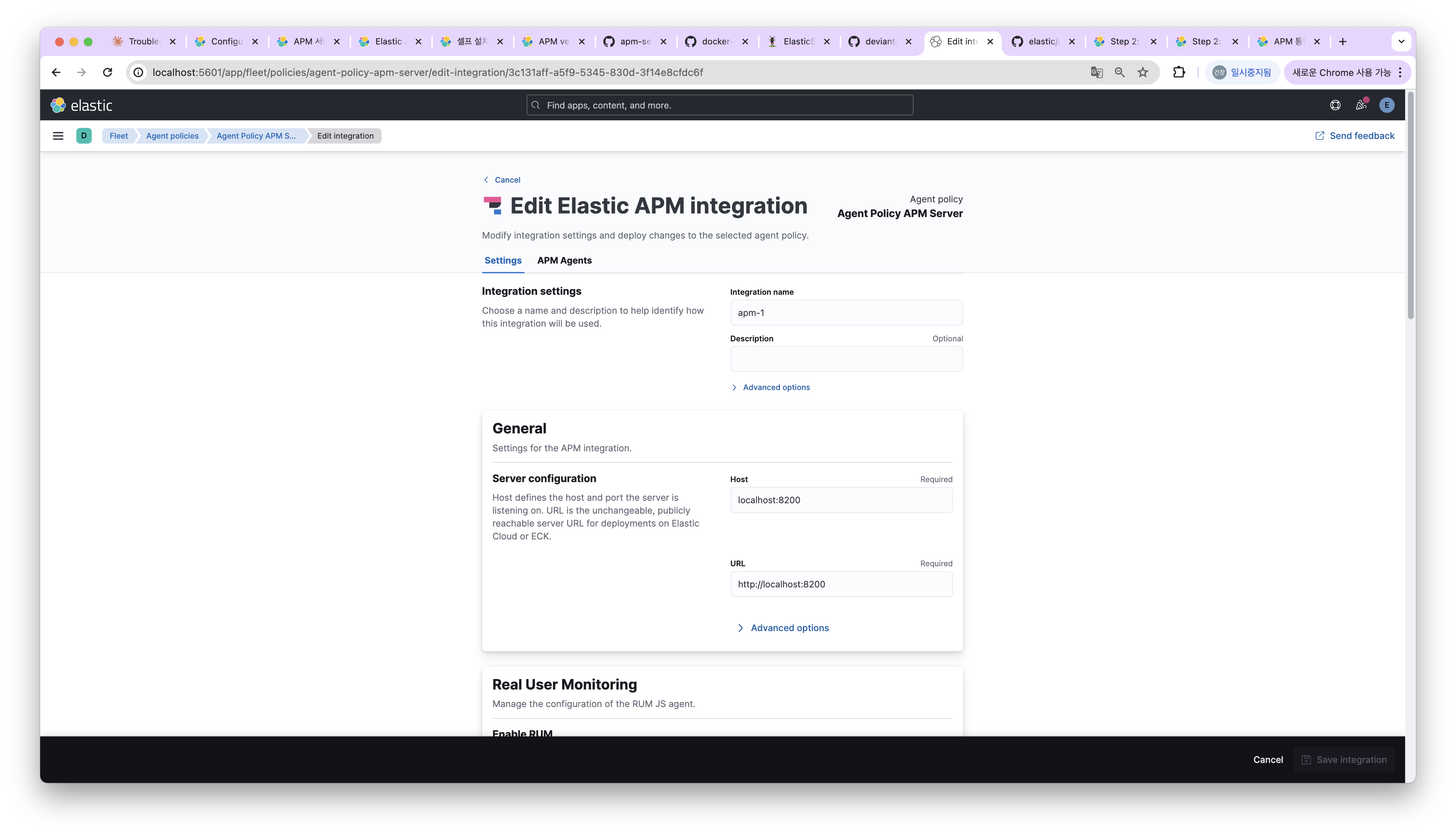
해당 apm ploicy에 들어가 자신의 apm host를 설정해주자.
Self-hosted apm server 트러블 슈팅 3 - The APM integration must be upgraded.
apm integration에 맞는 버전을 실행하지 않으면 다음과 같은 에러가 발생한다. elasticsearch, kibana 버전 8.14에 맞게 유지했지만 apm integration에서는 다른 버전이 설치되어 발생했다.
{
"log.level":"error",
"@timestamp":"2024-07-02T17:13:01.044+0900",
"log.origin":{
"function":"github.com/elastic/go-docappender.(*Appender).flush",
"file.name":"go-docappender@v1.1.1/appender.go",
"file.line":376
},
"message":"failed to index documents in 'metrics-apm.service_summary.1m-default' (fail_processor_exception): Document produced by APM Server v8.14.2, which is newer than the installed APM integration (v8.11.0-preview-1695749054). The APM integration must be upgraded.",
"service.name":"apm-server",
"documents":2,
"ecs.version":"1.6.0"
}
apm integration 에 설정된 fleet → agent policies → 확인하려는 integration 선택하면 해당 페이지가 열리고 버전도 해당 페이지에서 확인할 수 있다.
Fleet managed apm server
fleet managed apm server는 elastic agent로 관리되는 apm server 사용을 의미한다. fleet을 통해 한 개 이상의 elastic agent를 관리할 수 있고, elastic agent를 통해 apm server를 쉽게 사용할 수 있다. 즉, 처리량 늘어나는 현상을 스케일링으로 쉽게 해결 가능하다.
이때 주의할 점은 RUM을 사용하는 상황이다. RUM을 사용할 때에는 동일한 apm server를 사용해야 하기 때문에 스케일링으로 재배치하는 경우를 신경써야 한다.
fleet 서버 생성은 생각보다 쉽다. 단순하게 fleet management에 접속해 Add Fleet Server 절차를 따라가면 된다.
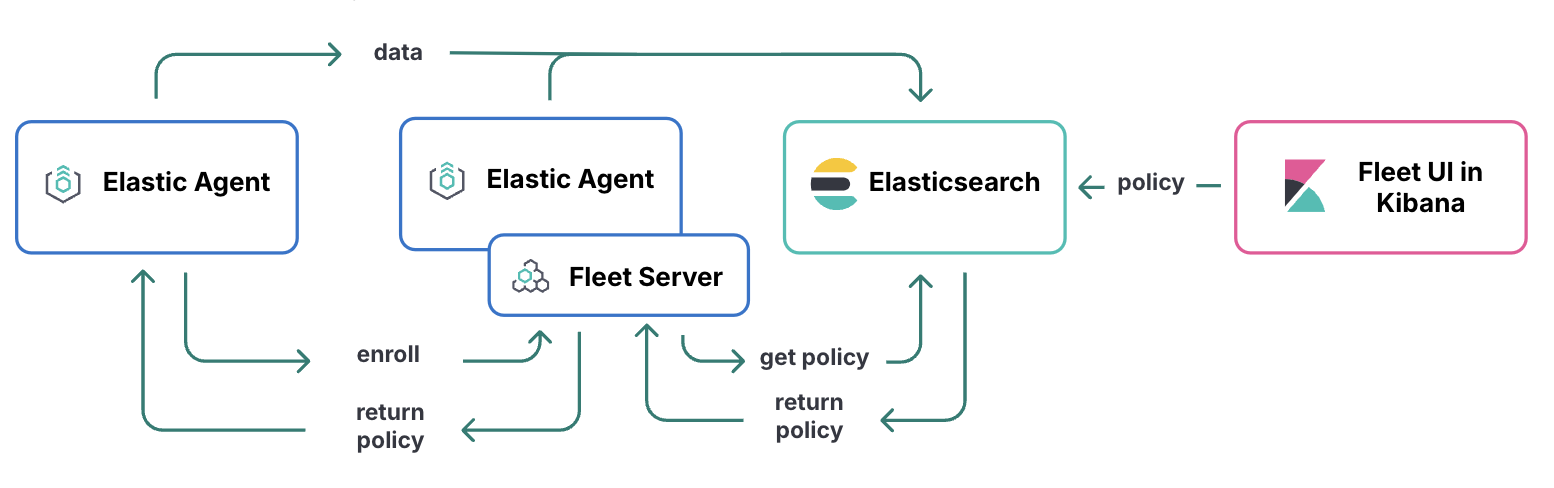
fleet 서버를 너무 어렵게 생각하지 않아도 된다. 그냥 elastic agent를 관리하는 fleet 기능을 가진 elastic agnet다.
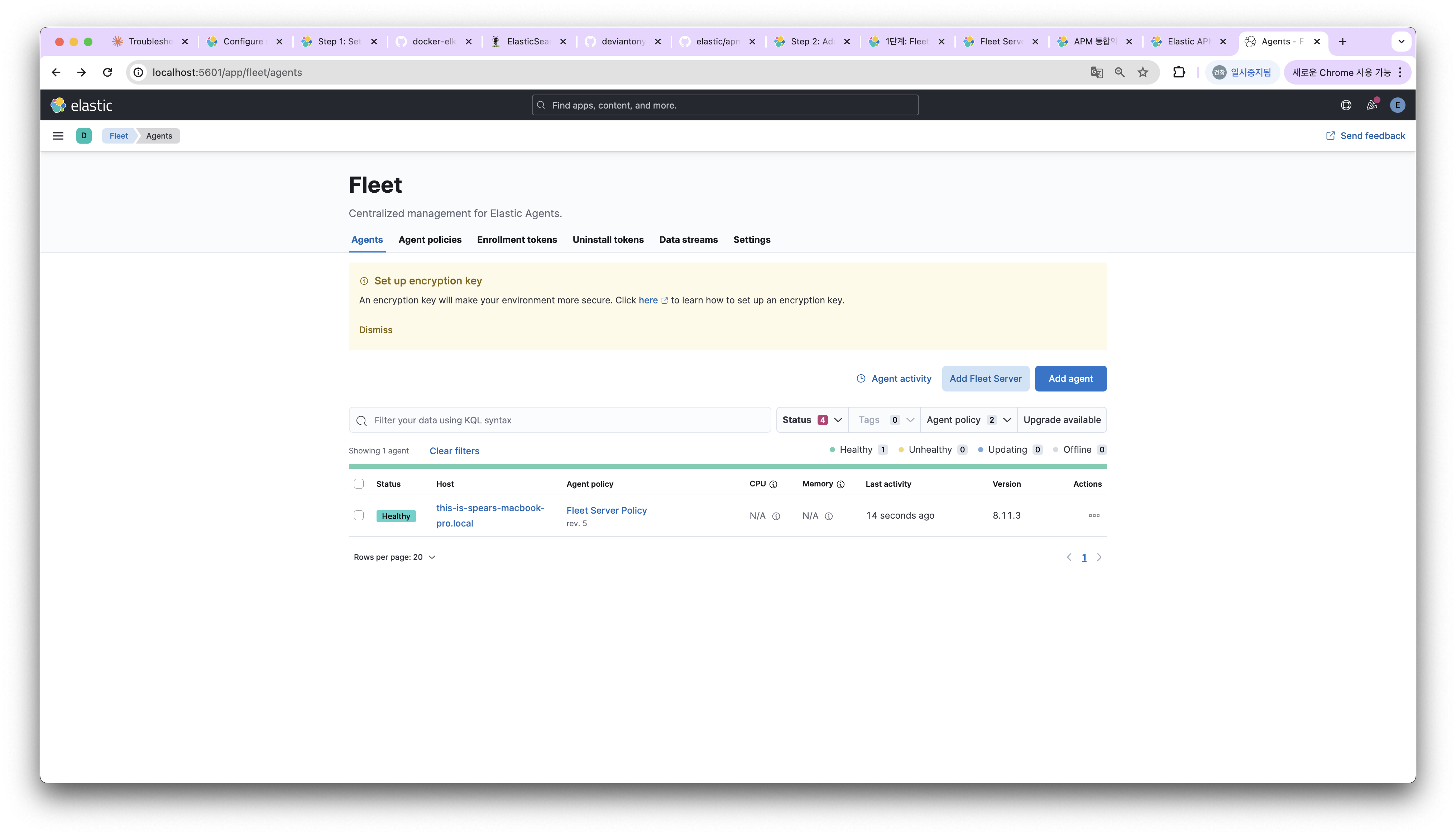
Fleet Server를 등록하면 다음처럼 확인 가능하다.
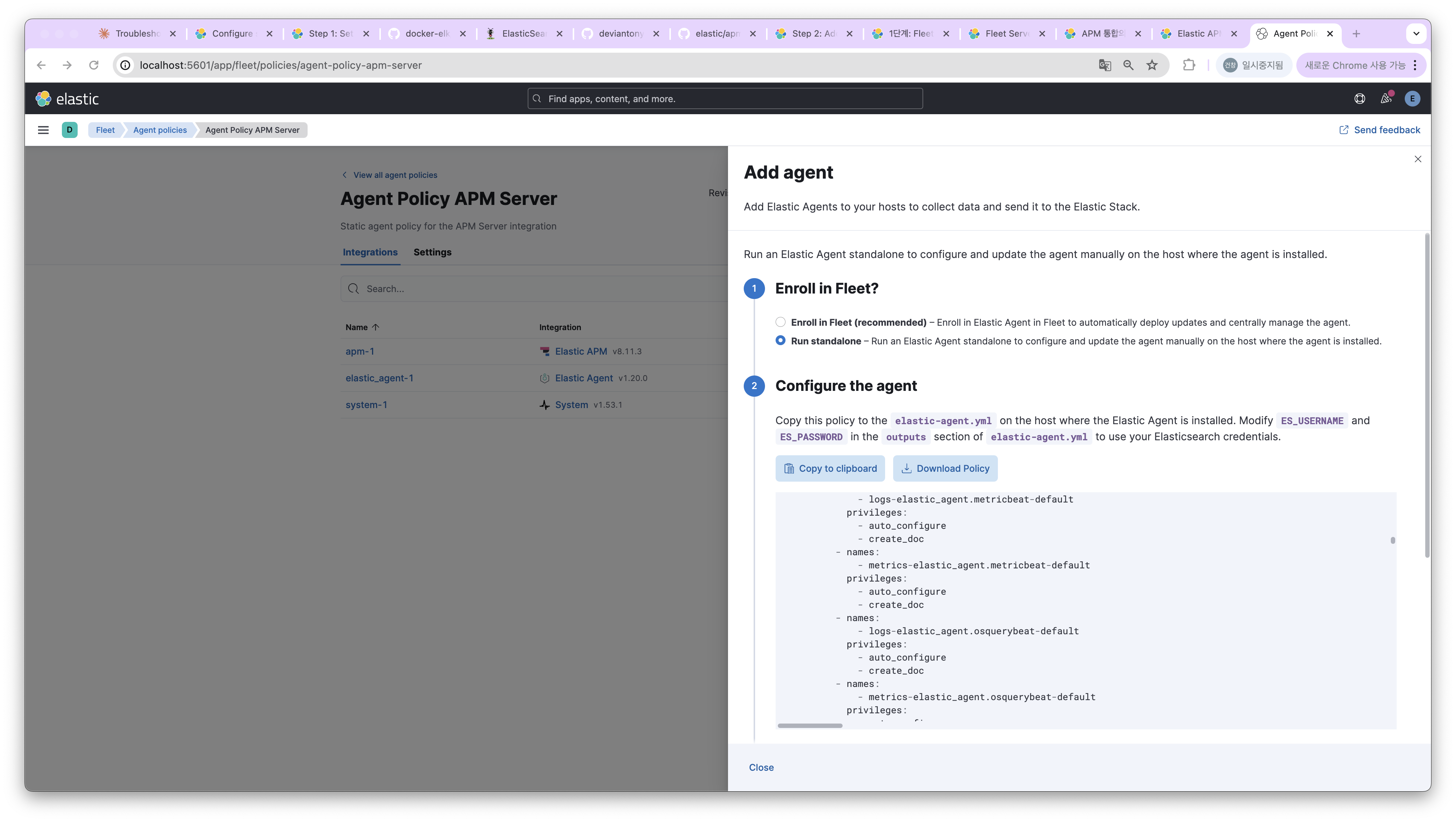
지금은 서버 한 대로 테스트하다보니 동일한 Agent를 두 개 이상 띄울 수 없었다. 간단하게 Fleet Server 없이 Agent만 등록해서 진행해보겠다. Elastic Agent를 Run standalone 형식으로 실행하면 된다. 다음 절차로 Agent를 추가하면 된다.
정상 실행됐는지 확인하기 위해서 apm server로 GET / 요청을 보내면 된다. publish_ready가 true면 요청 받을 준비가 된 것이다.
curl http://localhost:8200
{
"build_date": "2023-12-07T11:11:14-05:00",
"build_sha": "cba21e88bd0d376ec77dc77fccccfdc0c27206ac",
"publish_ready": true,
"version": "8.11.3"
}
Fleet managed apm server 트러블 슈팅 1 : publish ready false
Fleet Server는 배포된 Elastic Agent 내부에서 실행되는 하위 프로세스이니 해당 Elastic Agent로 APM 데이터를 수집하면 되지 않을까 생각할 수 있지만 그렇지 않다. 해당 에이전트는 Elastic Agent 통신 호스트로 Fleet Server를 실행하는 데 전념하며 데이터 수집을 위해 구성되지 않는다.
Fleet Server에서 apm integration 설정을 진행하면 다음처럼 준비가 되지 않았다는 이슈가 발생한다.
curl http://localhost:8200
{
"build_date": "...",
"build_sha": "...",
"publish_ready": false,
"version": "..."
}
Fleet managed apm server 트러블 슈팅 2 : agnet가 추가 안돼요!
Fleet Server는 등록하자마자 Agents 에 숫자가 카운팅되지만 Fleet Server 없이 추가하면 카운팅되지 않으니 신경쓰지 말자.

대부분의 Agent 관리 기능은 Fleet Server가 있어야 가능하니 이런 상황이 발생해도 그려러니 해야 한다. 원하는 기능을 사용할 수 있는지 여부는 해당 포트로 요청을 보내서 확인하자.
curl http://localhost:8200
{
"build_date": "2023-12-07T11:11:14-05:00",
"build_sha": "cba21e88bd0d376ec77dc77fccccfdc0c27206ac",
"publish_ready": true,
"version": "8.11.3"
}
Apm agent의 가능성
apm agent에는 metricbeats, filebeats, apm 등을 구성할 수 있고, inputs에 원하는 입력을 추가하면 쉽게 핸들링 가능해서 활용할 수 있는 방안이 많다. 다음처럼 inputs에 원하는 입력 형태를 추가하면 된다.
...
inputs:
- type: filestream
id: unique-id-per-input
paths:
- /var/log/my-application/log-file.log
https://www.elastic.co/guide/en/fleet/current/elastic-agent-simplified-input-configuration.html
아니면 filebeat를 사용하지 않더라도 log_sending 옵션을 이용해 apm으로 로그를 전송할 수 있다. 해당 글에서 확인할 수 있지만, 일부 로그가 유실될 수 있으니 주의하자.
만약 MDC를 지원하고 싶다면 log_ecs_reformatting 옵션을 이용하면 된다. 해당 글에서 확인할 수 있다.
클라이언트에서 에이전트 등록
클라이언트에서 에이전트를 등록하는 방법은 다양하지만 필자는 프로젝트에 비즈니스와 관련되지 않은 코드는 추가하고 싶지 않았다. 그래서 컨테이너를 만드는 시점에 추가할 수 있도록 구현했다.
FROM amazoncorretto:17
COPY /usr/agent/elastic-apm-agent.jar /elastic-apm-agent.jar
ARG JAR_FILE=build/libs/*.jar
ENV APM_ENVIRONMENT="dev"
ENV APM_SERVER_URL="http://apm-server:8200"
ENV APM_TOKEN=""
COPY ${JAR_FILE} app.jar
CMD java -javaagent:elastic-apm-agent.jar \
-Delastic.apm.service_name=service-api \
-Delastic.apm.secret_token=$APM_TOKEN \
-Delastic.apm.server_url=$APM_SERVER_URL \
-Delastic.apm.environment=$APM_ENVIRONMENT \
-Delastic.apm.application_packages=com.hello \
-jar app.jar
사용할 수 있을법한 옵션과 함께 설명을 정리했다.
| 환경 설정 정보 | 설명 | 예시 |
|---|---|---|
| elastic.apm.service_name | 서비스를 식별할 수 있는 이름을 설정한다. | member-api |
| elastic.apm.environment | 해당 서비스가 실행되는 환경을 의미한다. dev, aplus-test, aplus-qa, aplus-stage, aplus-prod | dev |
| elastic.apm.server_url | apm 이 세팅된 URL을 의미한다. dev, test, qa 환경은 http://10.9.25.4:8200 에 위치한다. | http://apm-server:8200 |
| elastic.apm.secret_token | 연결에 필요한 secret token 값이며 apm integration에서 설정할 수 있다. | |
| elastic.apm.application_packages | 연결할 서비스의 application 패키지명이다. 컨텍스트 서치가 되는 루트 패키지로 설정한다. | com.hello |
| elastic.apm.enable_experimental_instrumentations | experimental 기능을 사용할지 결정하는 옵셔이다. experimental 기능을 사용한다면 꼭 추가해야 한다. | true |
| elastic.apm.log_sending | 로그를 직접 전송하는 방법이다. Filebeat를 사용하는게 좋지만 사용하지 않는다면 추가해도 좋다. - 참고글 | true |
클라이언트에서 에이전트 등록 트러블 슈팅 1 - Route Unkown
해당 형식처럼 어떤 요청을 받았는지 확인하기 어려운 상황이 있다.

APM은 요청을 처리한 서블릿 이름으로 분류하게 되는데 서블릿에 도달하지 않으면 해당 형식으로 지정된다. Spring Cloud Gateway는 성능을 위해 서블릿을 거치지 않고 라우팅하게 되어 서블릿 이름을 설정할 수 없게 된다. 관련 글은 해당 글에서 확인 가능하다.
이런 경우 java agent에서 elastic.apm.use_path_as_transaction_name 플래그를 true로 설정하면 된다. 다만 URL 기반으로 생성되게 되는데 path parameter가 추가되면 대량 트랜잭션이 발생할 수 있으니 주의해야 한다. 이런 경우 url groups를 이용해 트랜잭션이 대량 발생하지 않도록 주의하자.
운영환경 이슈 트러블 슈팅 1 - Data too large
운영 환경 kibana에 접속하자마자 해당 이슈와 맞딱뜨렸다. 15분 간격으로 데이터를 조회하는 쿼리가 허용된 크기보다 10MB 초과해서 요청이 중단됐다.
Error while fetching resource
Error
[parent] Data too large, data for [<http_request>] would be [1034040064/986.1mb],
which is larger than the limit of [1020054732/972.7mb], real usage: [1034040064/986.1mb],
new bytes reserved: [0/0b],
usages [model_inference=0/0b, inflight_requests=0/0b, request=0/0b, fielddata=52192/50.9kb, eql_sequence=0/0b]:
circuit_breaking_exception Root causes: circuit_breaking_exception: [parent] Data too large, data for [<http_request>] would be [1034040064/986.1mb],
which is larger than the limit of [1020054732/972.7mb],
real usage: [1034040064/986.1mb], new bytes reserved: [0/0b], usages [model_inference=0/0b, inflight_requests=0/0b, request=0/0b, fielddata=52192/50.9kb, eql_sequence=0/0b] (429)
URL
https://host/internal/apm/fallback_to_transactions?kuery=&start=2024-07-03T10%3A14%3A34.049Z&end=2024-07-03T10%3A29%3A34.049Z
다음 이슈에서 circuit_breaking_exception 임을 확인할 수 있었다. 해당 글에서는 OOM을 막기 위해 제한이 걸리기 때문에 제한 설정을 변경하지 않아야 하며 요청을 분할할 수 있도록 설정할 필요함을 알게 됐다.
Error
[circuit_breaking_exception Root causes: circuit_breaking_exception:
[parent] Data too large,
data for [<http_request>] would be [1023057920/975.6mb],
which is larger than the limit of [1020054732/972.7mb],
real usage: [1023057920/975.6mb], new bytes reserved: [0/0b], usages [model_inference=0/0b, inflight_requests=0/0b, request=0/0b, fielddata=57630/56.2kb, eql_sequence=0/0b]]:
[parent] Data too large,
data for [<http_request>] would be [1023057920/975.6mb],
which is larger than the limit of [1020054732/972.7mb],
real usage: [1023057920/975.6mb], new bytes reserved: [0/0b], usages [model_inference=0/0b, inflight_requests=0/0b, request=0/0b, fielddata=57630/56.2kb, eql_sequence=0/0b] (429)
그럼 생각할 수 있는 내용은 JVM 제한에 맞게 서킷 브레이커가 걸리고 요청 분할로 해결 할 수 있음을 나타낸다. 첫 번째로 JVM 관련 설정을 제어하는 방법을 고려했다. 해당 글에서는 제한을 수정하는 방식을 제안했다.
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient" : {
"indices.breaker.total.limit" : "80%"
}
}
'
이런저런 글을 찾아보니 JVM 허용량을 기준으로 상한선이 정해지게 되는데, 운영 환경 ES 사이즈가 너무 작아 발생하는 문제처럼 보인다.
운영환경 이슈 트러블 슈팅 2 - 늘어나는 데이터셋
JVM 리소스도 걱정되는데 저장 공간은 괜찮을까 우려됐다. 최근 신규 서비스를 런칭하면서 APM이 추가됐는데 6월 2일부터 7월 3일까지 적재된 양만 81GB다. 새로운 서비스가 추가되면 쌓이는 양이 3배 가까이 늘어나게 되니 대책을 미리 강구해야 한다. 고민 포인트는 세 가지다.
- 스팬 압축
- 샘플링 관리
- 인덱스 라이프사이클 설정
스팬 압축 먼저 살펴보자면 애플리케이션에서 데이터를 조합하는 경우 두 개 이상의 SQL이 실행되면서 다량의 스팬이 생성될 수 있다. 이런 경우 복잡하기만 하고 한 눈에 파악하기 어려울 수 있다. 이런 경우 (1) 같은 유형 이거나 (2) 동일한 정보를 가지거나 패턴을 분석해 압축을 진행한다.
같은 유형인지는 스팬의 타입과 접근하는 리소스로 파악하며 동일한지는 스팬 값을 확인해서 판단한다. 자세한 내용은 해당 글에서 확인 가능하다.
span_compression_same_kind_max_duration: 주변 스팬 정보와 유사한 정보를 가지고 있는지 여부를 의미하며 동일한 span을 가진다면 같은 작업으로 인식한다. 기본 값은0ms이다.span_compression_exact_match_max_duration: 스팬 값이 정확히 일치하는지 여부를 의미하며 일정 기간 내에 동일한 span을 가진다면 같은 작업으로 인식한다. 기본 값은50ms이다.
🚧 스팬 압축의 단점은 SQL이 수집되지 않는다는 점이다. 주의하자.
샘플링을 관리하게 되면 데이터 양과 분석에 필요한 노력을 획기적으로 줄일 수 있다. 샘플링 덕분에 비정상적인 패턴을 쉽게 관리하고 복구 시간 또한 낮출 수 있다. APM은 head-based sampling 방식과 tail-based sampling 방식을 지원한다. 샘플링 값은 transaction_sample_rate 옵션으로 결정된다. 기본 값은 1이며 100%를 의미한다. 0.2라면 20%를 의미한다. 소수점은 네 자리만 지원하며 넘어갈 경우 반올림한다.
기본적으로 apm agent는 head-based sampling 방식을 지원하며 추적이 시작되는 경우에 샘플 여부를 결정한다. 즉 해당 그림에서는 Service A에서 샘플링 여부가 결정된다.
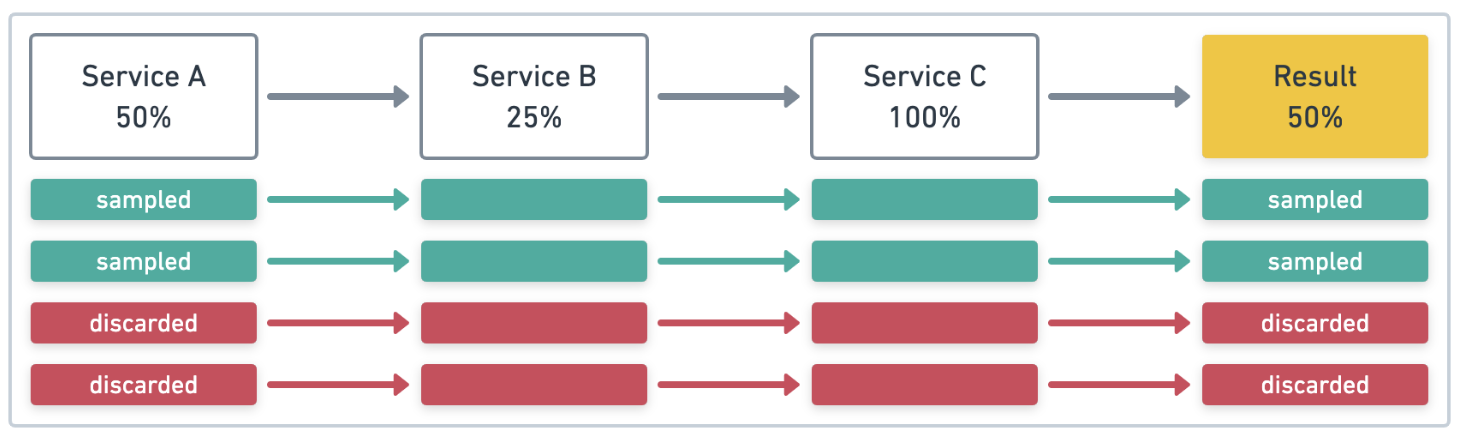
head-based sampling은 이후 오류를 예측할 수 없기 때문에 Service C에서 에러가 발생해도 샘플링이 불가할 수 있다. 이처럼 신뢰할 수 있는 샘플링 추출이 어렵기 때문에 tail-based sampling 방식을 고려해야 한다.
tail-based sampling 방식은 추적이 끝난 뒤에 샘플 여부를 결정한다. 샘플링 여부를 결정하는 요소 중 하나가 느린지 여부인데, 느릴 수록 샘플되어야 하기 때문이다. 이처럼 의미 있는 샘플이 추출될 가능성이 높다.
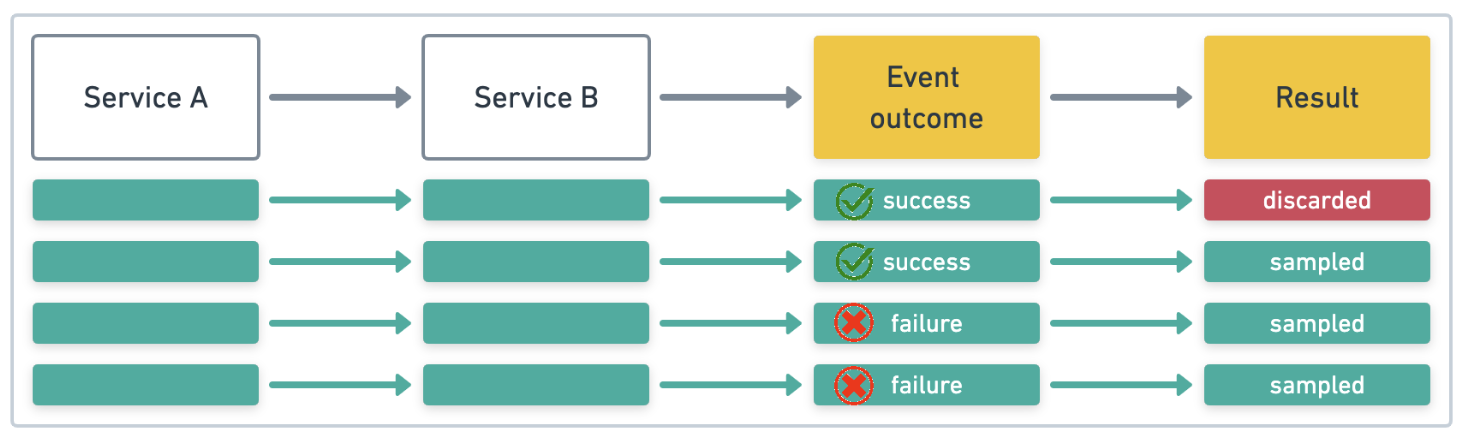
tail-based sampling 방식의 단점은 APM 서버에서 샘플링이 이루어지기 때문에 요구되는 CPU와 메모리가 많다. 결과적으로 ES에 전송되는 데이터 양은 적으니 ES 관리 부담은 줄일 수 있다.
tail-based sampling 방식은 APM 서버 설정이 필요하며 해당 글에서 관련 설정을 진행할 수 있다.
🚧
tail-based sampling방식에서 요구되는 APM 서버 메모리 양은 3GB이며 저장 한도가 부족하면configured storage limit reached.힌트를 제공한다.
마지막으로 인덱스 라이프사이클 설정 방식을 살펴보면 기본적으로 수명 주기가 설정되어 있다. 롤오버가 진행되면 일부 메트릭을 지우게 된다. 이런 형식의 인덱스가 있으며 롤 오버가 진행될 때마다 관리된다.

인덱스 라이프사이클을 수정할 필요는 없었다. 각 인덱스마다 데이터 사이즈 한도가 50GB이며, 월 단위로 관리된다. 롤 오버가 진행되면 30일이 지난 데이터를 제거하고 50GB가 넘지 않도록 정리하게 된다.
운영환경 이슈 트러블 슈팅 3 - Spring cloud gateway 추적 불가 이슈
게이트웨이를 거치면서 트랜잭션 전파가 정상적으로 동작하지 않았다. 문제 원인은 apm agent 트랜잭션이 web client, rest template, servlet 등 일반적인 API 통신만 지원하고 게이트웨이 전파 방식은 지원하지 않았기 때문이다. 그래서 헤더에 직접 삽입하는 방식으로 수동 전파를 이용해 해결했다. 수동으로 추가하기 위해 라이브러리를 추가한다.
implementation 'co.elastic.apm:apm-agent-api:1.50.0'
. void injectTraceHeaders(HeaderInjector headerInjector) 메서드 사용하면 쉽게 해결 가능하다. 추가한 코드는 다음과 같다.
private const val TYPE_EXTERNAL = "external"
private const val SUBTYPE_HTTP = "http"
private val ACTION = null
//...
val request = exchange.request
val spanName = request.methodValue + " " + request.uri.path
// 현재 span 정보 조회
val span = ElasticApm.currentSpan()
.startSpan(TYPE_EXTERNAL, SUBTYPE_HTTP, ACTION)
.setName(spanName)
val transaction = ElasticApm.currentTransaction()
try {
transaction.activate().use {
span.injectTraceHeaders { headerName: String, headerValue: String ->
request.mutate().header(headerName, headerValue).build()
}
chain.filter(exchange)
}
} catch (e: Exception) {
span.captureException(e)
throw e
} finally {
span.end()
}
//...
공식 문서는 transaction.activate() 사용하고 있었는데, 문맥상 span.activate() 하는게 맞지 않나 싶었다. activate() 는 간단하게 현재 사용하는 정보를 반환할 때 activate 한 정보를 반환한다. 예를 들어 ElasticApm.currentTransaction() 했을 경우 activate() 한 정보를 반환한다. 내부 구현체는 확인할 수 없었고 문서에서 지원하는 방식으로 진행했다. 글로벌 필터로 설정 후 결과는 다음과 같다.
AS-IS

TO-BE
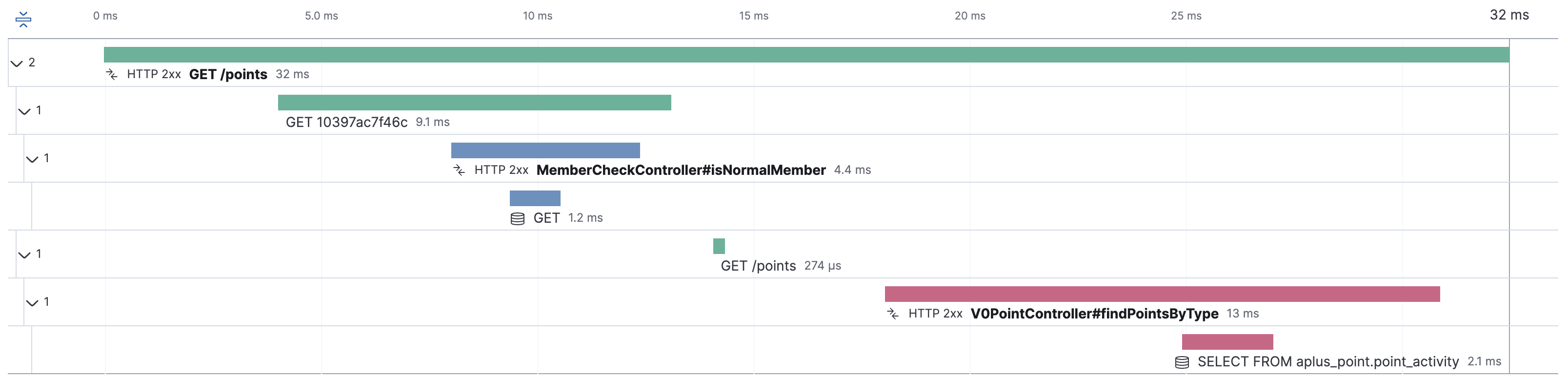
사용하면서 apm-agent-api에서 발생할 수 있는 이슈는 scop 객체로 인한 memory leak 이슈로 보인다. apm api 에서 제공하는 scope 는 closeable 구현체라서 닫아줘야 하니 주의하자.